수많은 RAG 모듈들의 조합으로 수많은 RAG 파이프라인이 생성될 수 있고 각 작업 도메인과 데이터 셋에 따라 최적의 RAG 파이프라인은 모두 다르다. (RAG 파이프라인의 수를 간단하게 계산해보자.) 심지어 prompt를 바꾸거나, LLM을 바꾸거나, 임베딩을 바꿀 때마다 기존 성능보다 더 좋아졌는지 나빠졌는지는 알 수 없다. 우리가 개발을 할 때도 테스트 코드를 짜듯이 RAG 파이프라인을 구성할 때도 테스트는 꼭 필요하다. 아니 오히려 LLM의 블랙박스적인 특징을 고려해 테스트의 중요성은 더 중요하다. 일반적으로 개발할 때 TDD라는 개발 방법론이 있는 것처럼 RAG를 개발할 때도 Evaluation Driven Development(EDD)라는 방법론을 도입하여 개발할 수 있다. RAG 서베이 논문 2편에 대해 Q&A를 할 수 있는 여러 RAG 파이프라인을 만들고 이들을 평가하기 위해 synthetic dataset을 만들어 가장 최적의 RAG 파이프라인을 선택하도록 할 것이다. 이를 구현하기 위해 블로그 의 내용을 참고하여 테스트 해보았다. 관련 코드는 github repo 에 올려두었다.
RAG Paradigm
Retrieval-Augmented Generation for Large Language Models: A Survey
을 보면 아래 그림처럼 Naive RAG, Avanced RAG, Modular RAG가 어떻게 다른지 소개한다.
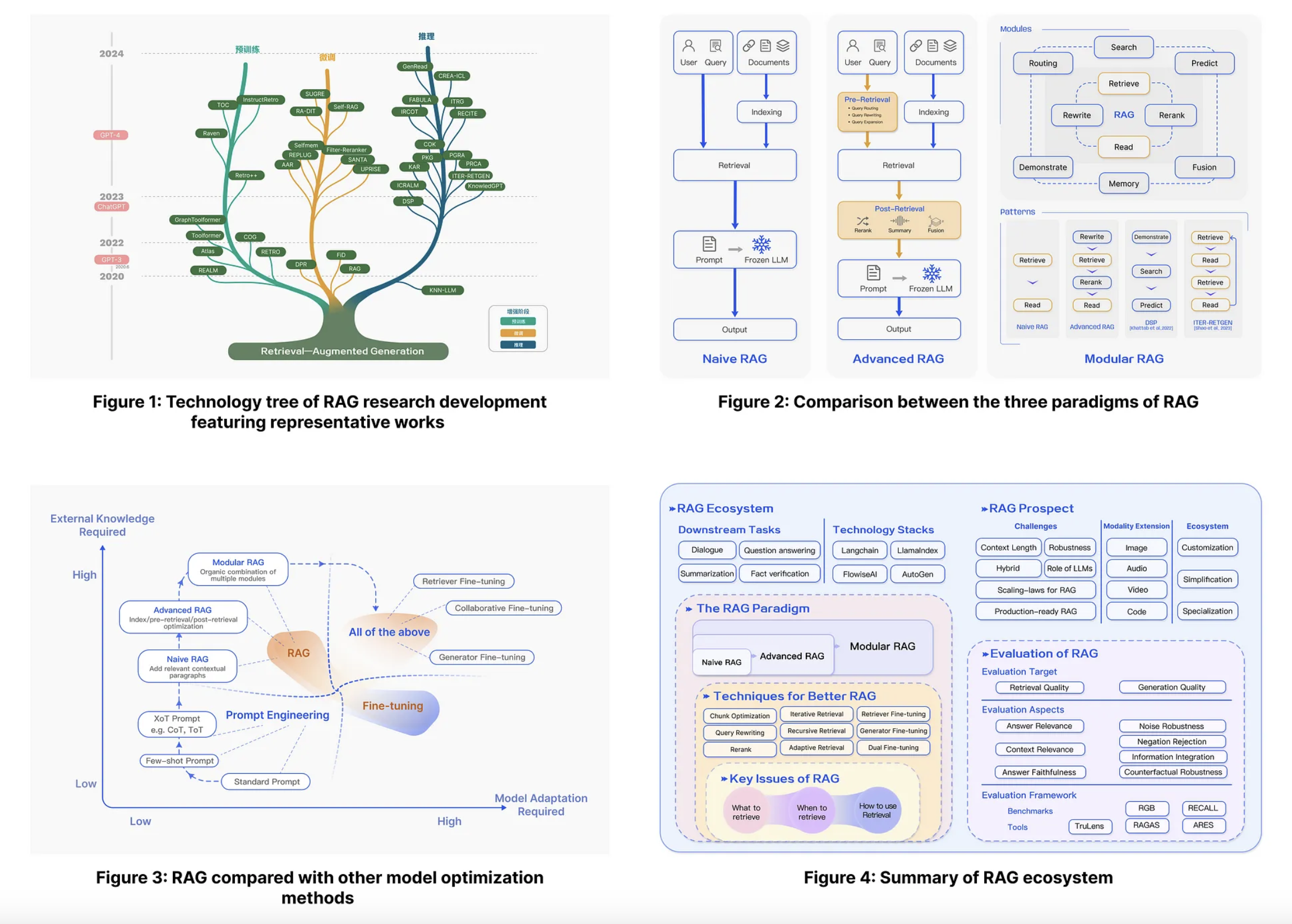
Naive RAG
가장 기본적인 형태의 RAG 파이프라인으로 크게 Indexing 단계와 Inferencing 단계로 나눌 수 있고 또 Inferencing 단계는 Retrieval과 Generation 단계로 또 나눌 수 있다. Indexing 단계에서는 pdf나 markdown 같은 다양한 데이터 포맷으로부터 plain text로 추출하고, LLM의 context 길이의 제한 때문에 plain text를 더 작은 chunk text로 잘라준다. chunk text는 임베딩 모델을 통해 벡터로 인코딩되어 저장된다. 그리고 Inferencing > Retrieval 단계에서는 쿼리를 Indexing 단계에서 사용했던 임베딩과 동일한 임베딩을 사용하여 벡터로 변환하고 이 임베딩과 저장된 임베딩 간의 유사도를 계산하고 내림차순으로 정렬하여 상위 K개의 chunk text 가져온다. Inferencing > Generation 에서 앞서 가져온 chunk text가 context로 사용되어 prompt와 함께 LLM에게 응답을 생성하도록한다.
이러한 Naive RAG에는 치명적인 단점이 여러 존재한다. Retrieval 단계에서 관련 없는 chunk를 선택하거나, 중요한 정보가 빠진 chunk를 선택하게 되면서 precision과 recall에 영향을 주게된다. precision은 간단히 말해서 정답이라고 예측한 것 중에 정답인 것의 비율이고 recall은 정답인 것 중에 정답이라고 예측한 것의 비율이다. 예를 들어, A, B, C, D, E 5개의 text chunk가 있다고 가정하자. 어떤 쿼리의 응답에 대한 정보가 들어있는 chunk가 A, B chunk 이고 (이게 정답이 된다) 정답이라고 예측한 chunk가 A, C, E chunk 라고 가정하자. 그럼 precision은 1/3 이고, recall은 1/2가 된다. 그래서 만약에 관련 없는 chunk라도 일단 많이 chunk를 가져오게되면, 정답 chunk가 포함될 확률이 높아질 것이니 precision은 줄어들고, recall은 올라가게 된다.
그리고 이후 응답을 생성할 때는 질문과 관련없는 context가 입력으로 주어질 경우 hallucination이 일어날 확률이 높아지기 때문에 hallucination을 제거하는 것이 중요한 도메인에 있다면 관련 없는 문서를 최대한 베제해야하고 앞서 retrieval 단계에서 precision을 높이는 것이 중요하다. 하지만 질문과 관련있는 context가 주어진다고 하더라도 context에서 질문과 관련없는 답변을 생성해내는 경우도 있다. 그리고 검색된 context가 반복되는 내용을 많이 담고 있으면 반복적인 응답이 발생할 수도 있고, context에 너무 의존적인 답변을 생성하거나, 아니면 반대로 너무 상관없는 내용을 생성할 수도 있으니 이를 방지하기 위한 모듈이 파이프라인 내에 필요하게 된다.
Advanced RAG
Advanced RAG는 Naive RAG의 단점을 극복하기 위해 Retrieval 앞 뒤로 pre-retrieval, post-retrieval 단계를 추가했다. pre-retrieval 단계에서는 검색되는 품질 자체를 높이기 위한 Indexing 과정의 퀄리티를 높이거나 사용자의 쿼리를 최적화한다. Indexing 과정에서 메타데이터를 따로 추가하거나(pdf의 페이지 쪽수, 최근 수정된 날짜 등) 다양한 chunking 로직을 도입할 수도 있다. 또 사용자의 쿼리를 rewriting, transformation, expansion을 하는 다양한 기법을 도입한다. 그리고 post-retrieval 단계에서는 검색된 context를 효과적으로 generation 단계의 입력으로 넣어주기 우해 reranking, context compressing 등의 기법이 사용된다. LLM은 prompt의 가운데 오는 정보를 잘 인식하지 못하는 특성이 있기 때문에 중요한 context 정보의 순위를 매겨서 prompt의 앞, 뒤에 재배치하는 것이 중요하다. 그리고 너무 많은 정보를 prompt에 입력하면 중요한 정보에 찾지 못할 가능성이 높아지기 때문에 중요한 정보를 중심으로 압축하여 generation 성능을 높일 수 있다.
Modolar RAG
Modular RAG는 Advanced RAG에서 새로운 RAG module과 새로운 RAG flow를 추가하여 adaptability(적응성, 변화하는 요구 사항에 얼마나 잘 적응하는지)와 versatility(다양성, 다양한 기능을 수행할 수 있는 능력을 의미)를 높인다. 기존의 plain text를 넘어 knowledge graph, structured data 형태의 데이터 소스에 대한 검색과 검색 엔진을 통한 검색까지 확장하여 벡터 DB에 대한 의존도를 줄였다. 그리고 search module 뿐만 아니라 fine tuning 한 retriever, generator을 통합하거나, memory module, adapter module 등도 추가로 통합할 수 있다. 또한 single query에 대해 read하고 write 하는 고정된 flow에서 벗어난 쿼리를 확장하여 다중 벡터 검색을 지원하거나, read-write 프로세스를 반복적으로 지원하기도 한다. 이렇게 modular RAG는 다양한 module과 flow를 유연하게 구현할 수 있도록 하는 방식을 제안한다. Naive RAG는 Advanced RAG의 특수한 경우이고, Modular RAG는 Advanced RAG의 sequence 자체가 확장되고 또 그 sequence 들이 결합된 경우라고 생각하면 될 것 같다.
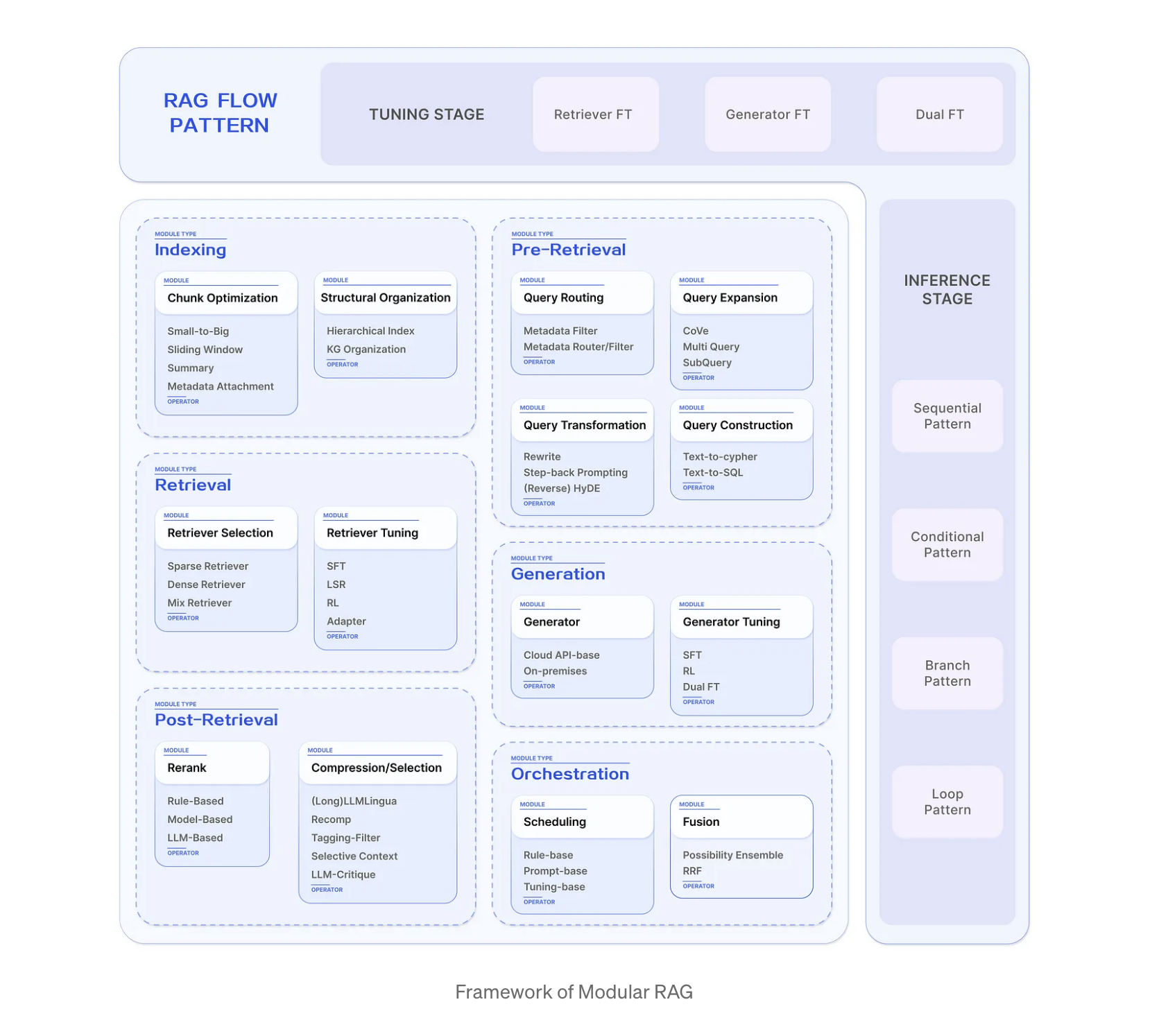 https://medium.com/@yufan1602/modular-rag-and-rag-flow-part-ii-77b62bf8a5d3
https://medium.com/@yufan1602/modular-rag-and-rag-flow-part-ii-77b62bf8a5d3
위 블로그에 다양한 RAG Flow 패턴들이 정리되어 있으니 참고해봐도 좋다.
RAG Evaluation
Retrieval
검색의 성능을 평가하는 것은 굉장히 오래된 주제이다. 검색 결과를 정답 레이블과 비교할 때 일반적으로 rank-agnostic 메트릭(검색 결과의 순서를 고려하지 않음)과 rank-aware 메트릭(검색 결과의 순서를 고려함) 두가지가 존재한다. 이 두 종류의 메트릭 모두 정답 레이블이 필요하다.
rank-agnostic metrics
- Precision: 검색된 것 중 정답 비율
- Recall: 정답 중 검색된 컨텍스트의 비율
- F1: precision과 recall의 조화평균
rank-aware metrics
- Mean Reciprocal Rank(MRR)
- Mean Average Precision(MAP)
- Normalized Discounted Cumulative Gain(NDCG)
자세한 내용은 Evaluation Metrics For Information Retrieval 의 글을 참고하자.
Generation
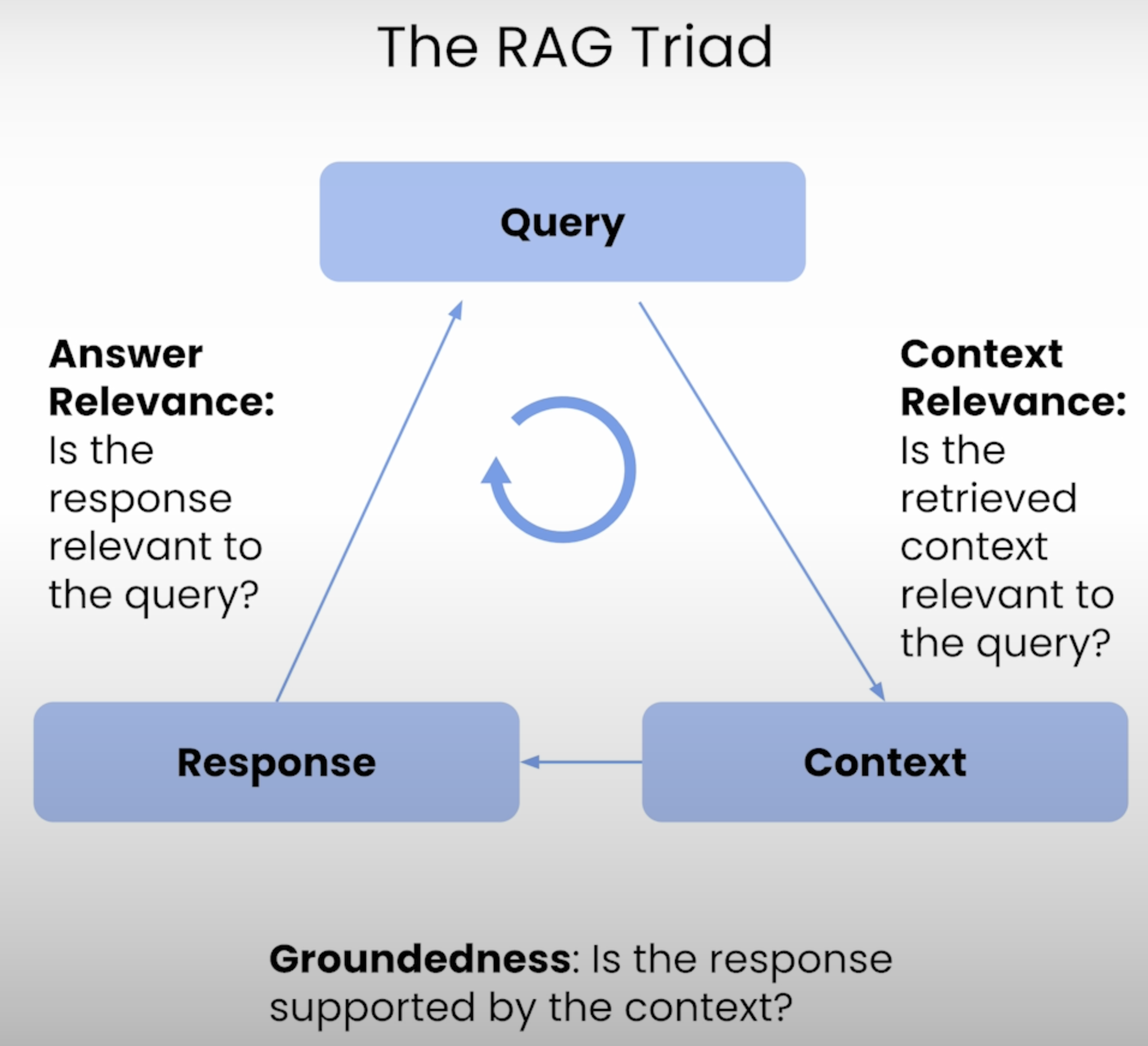
Generation을 평가하는 것은 LLM에서 생성된 답변을 평가하는 것이다. 이는 답변이 주관적이고 맥락에 따라 달라지기 때문에 검색을 평가하는 것보다 더 어렵다. $Q$(질문), $C$(검색된 컨텍스트), $C*$(정답 컨텍스트), $A$(생성된 답변), $A*$ (정답 답변)이 있다고 했을 때 대표적으로 아래 3가지 메트릭이 존재할 수 있다.
- Correctness: $A$, $A*$ 간에 유사한 정도
- Faithfulness(Groundedness): $A$의 답변이 $C$와 얼마나 관련 있는지. 업스테이지 블로그 LLM의 환각 현상을 해결하는 RAG 및 Groundedness Check 를 보면 응답이 참조 문서의 내용과 일치하는지를 체크하는 것을 Groundness check 라고 한다고 한다.
- Answer Relevance: $A$가 $Q$ 질문에 답하고 있는지
- Context Relevance: $C$가 $Q$와 얼마나 관련이 있는지
그림으로 나타내면 다음과 같다.
 https://www.deeplearning.ai/short-courses/building-evaluating-advanced-rag/
https://www.deeplearning.ai/short-courses/building-evaluating-advanced-rag/
Build RAG pipeline
Indexing
Survey paper의 document를 분할할 때 pdf의 기본적인 layout 구조를 유지한채 분할하기 위해 llamahub에서 제공하는 SmartPDFLoader 를 사용했다. nested sections, nested lists, paragraphs, tables 구조를 이해하고 분할한다. Embedding 모델은 openai의 text-embedding-ada-002를 사용했으며 VectorStore는 1 GB RAM, 45GB의 Elasticsearch 인스턴스 1대를 생성하여 사용했다. Indexing 과정에서 chunk text 마다 요약, 제목, 질문&답변 등의 메타데이터를 추출할 수 있는 여러 extractor도 함께 제공하고 있다. 여러 extractor로 구성된 transformations을 정의하고 넣어주면 node 객체의 metadata로 추가되지만 llm을 호출하여 메타데이터를 생성하다보니 시간이 너무 오래걸려 생략하고 실험을 진행했다.
summary_extractor = SummaryExtractor()
title_extractor = TitleExtractor(nodes=10)
qa_extractor = QuestionsAnsweredExtractor(questions=2)
transformations = [summary_extractor, title_extractor, qa_extractor]
index = VectorStoreIndex.from_documents(
documents=documents,
transformations=transformations,
show_progress=True
)
이렇게 chunk optimization을 진행할 때 metadata extraction말고도 small-to-big 방법도 존재한다. chunk size를 작게 유지하면 검색이 잘되고 chunk size를 늘리면 더 많은 context 정보를 제공할 수 있다. 그래서 retrieve 되는 chunk와 generate 되는 chunk를 분리하여 retrieve 할 때는 작은 chunk를 사용하고 generation 할 때 parent chunk를 가져오거(Auto-merging retrieval)나, 아니면 window size 내에 있는 chunk를 가져와서 더 큰 chunk를 넣어줄 수도 있다(Sentence-window retrieval). 하지만 아래 실험에서는 생략했다.
아래와 같은 형태로 총 311개의 text chunk가 추가되었다.
Inferencing
Inference 단계에서 llm은 gpt-3.5-turbo를 사용했다. pre-retrieval 단계에서는 hyde와 query decomposition 모듈을, retrieval 에서는 bm25와 bm25, knn을 함께 사용하는 hybrid search 모듈을, 그리고 post-retrieval 에서는 colbert rerank와 cohere rerank를 모듈을 사용했다. Rerank 모듈을 구현할 때는 retrieval에서 코사인 유사도가 높은 상위 10개의 문서를 가져온 후 rerank score가 높은 상위 5개의 문서를 가져와서 source context로 사용하도록 했다. 위에서 구현한 각 단계의 모듈들을 조합하여 baseline을 제외한 6개의 RAG Flow를 만들었고 baseline과 비교하여 RAG survey paper QA task에서 가장 성능이 좋은 RAG pipeline을 선정했다. 예를들어 hyde, hybrid search, colbert rerank을 조합한 RAG flow는 아래와 같다.
# pre-retrieval
hyde_transform = QueryTransformModule.hyde_query_transform(llm=llm)
# retrieval, indexing
index = ElasticSearchVectorStoreModule(
index_name=index_name, embedding=embedding, retrieval_strategy=RetrieverStrategyEnum.HYBRID
).get_index()
# post-retrieval
colbert_rerank = RerankModule.colbert_rerank(top_n=5)
# query
query_engine = TransformQueryEngine(
query_engine=index.as_query_engine(
llm=llm,
similarity_top_k=10,
node_postprocessors=[colbert_rerank],
),
query_transform=hyde_transform,
)
query_engine.query(query)
Synthetic Dataset
RAG의 성능을 향상시키기 위해 각 컴포넌트를 수정할 수 있다. 하지만 전체 시스템에 어떤 영향을 미칠지 미리 알 수 없으므로 구성 요소를 쉽게 변경할 수 없다. RAG의 성능을 평가할 수 있는 합성 데이터 셋을 만들기 위해 소스 문서를 읽어와서 예상 질문과 답변을 생성하는 question generator와 그것들이 올바르게 생성되었는지를 확인하기 위한 critique generator가 사용된다.
Question generator
LLM을 사용하여 합성 평가 데이터 셋을 생성한다. 소스 문서 데이터는 RAG와 관련된 survey 논문 두편이고, gpt-4o 모델을 사용하여 QA쌍을 생성했다. gpt-4o 모델이 2023년 10월까지의 데이터셋으로 학습 되었기 때문에 이 때 사용한 소스 문서는 그 이후에 나온 논문들을 사용했다. 그리고 이 때 lost in the middle 문제 때문에 소스 문서의 처음과 끝에 있는 내용을 가지고만 질문을 만드는 현상을 발견할 수 있었는데, 텍스트의 특정 부분이 겹치면서(chunk_overlap: 32) 일정 크기로 자르도록(chunk_size: 512)하여 문서 전체에서 골고루 질문을 수정하도록 문서를 자르고 질문을 생성하도록 했다.
Critique generator
Critique generator는 임시로 만들어진 합성 데이터 셋을 평가하는 역할을 하며 question과 context와 관련있는지, question과 answer이 관련있는지, 그리고 그 질문에 대한 답변을 생성하는데 있어서 추가적인 정보나 컨텍스트가 없이도 명확하게 이해할 수 있는지를 확인하는 3가지 지표를 사용한다. 각 지표의 점수를 1에서 5점 scale로 설정하여, 세 지표가 모두 4점보다 큰 question만 선택되도록 했다. 전체 350개의 질문, 맥락, 답변 데이터 셋이 생성되었지만 critique generator의 평가를 거친 후 161개의 데이터 셋이 선택되었다.
Evaluation Experiments
결과는 아래와 같다.
| RAG Flow | Answer correctness score |
|---|---|
| baseline | 0.658 |
| baseline + hyde | 0.676 |
| baseline + query decompose | 0.397 |
| baseline + hyde + bm25 | 0.750 |
| baseline + hyde + hybrid | 0.768 |
| baseline + hyde + colbert rerank | 0.787 |
| baseline + hyde + hybrid + cohere rerank | 0.820 |
Reference
[LlamaIndex] Component Guide Docs
[Langchain] RAG from scratch
Modular RAG and RAG Flow
RAG Evaluation
[OpenAI] A Survey of Techniques for Maximizing LLM Performance