배달의 민족
[우아콘 2020] 배달의민족 마이크로서비스 여행기 발표영상
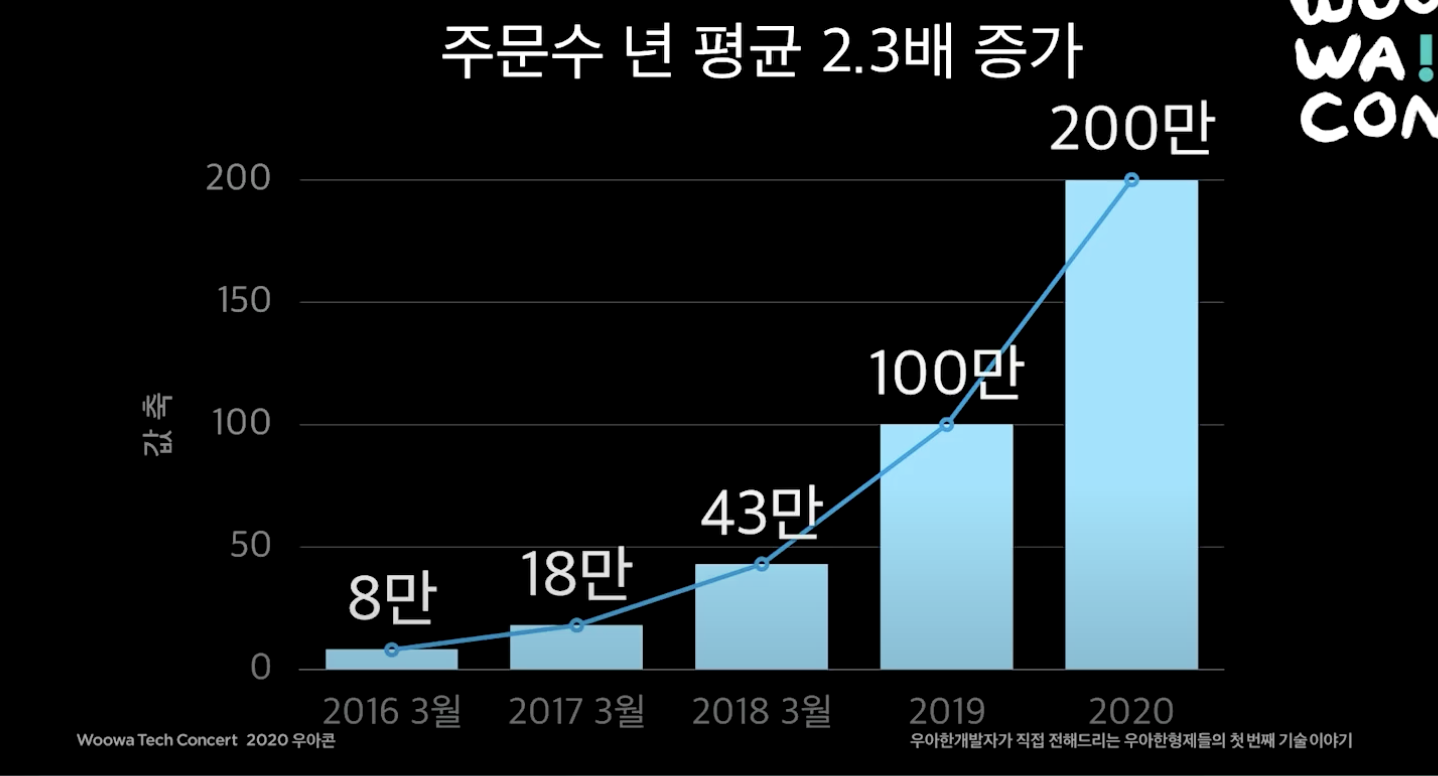
을 정리한 글이다. 5년동안 배달의 민족의 트래픽은 매년 평균 2.3배가 증가할 정도로 급성장한 서비스이다. 이 과정동안 개발팀에서는 어떤 일이 있었는지을 알아본다.
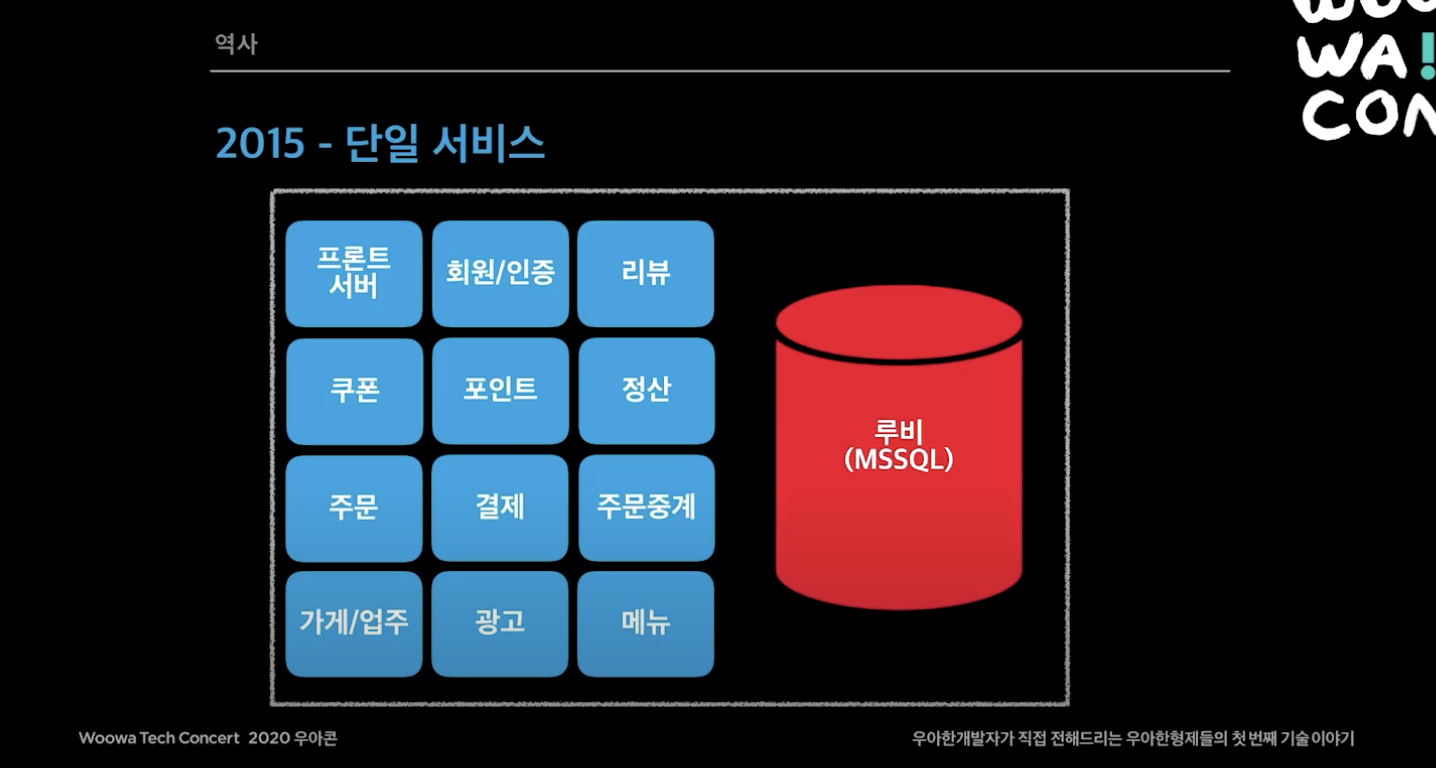
2015년
- 하루 주문수 5만 이하
- MSSQL + PHP, ASP
- 루비 DB(MSSQL)를 사용. 테이블이 700개가 넘었음.
- 대부분 루비 DB의 스토어드 프로시저 방식으로 사용함. 4000개 정도 사용하고 있었음.
- 굉장히 거대한 모놀리틱 시스템. 루비 DB 장애시 전체 서비스 장애로 이어짐. 한 예시로 리뷰 시스템에 장애가 났는데, 고객이 주문을 못하는 상태가 됨.
2016년
- 하루 주문수가 10만을 돌파함.
- php에서 자바로 옮길 계획을 세움. 자바를 선택한 이유로 첫째는 대용량 트래픽 대응을 위한 기술을 안정적으로 제공할 수 있고, 두번째는 개발자 수급 문제를 해결해야 했음.
- 마이크로서비스 도전 시작. 마이크로서비스로 넘어가는 것은 생존의 문제였고 여기서 마이크로서비스라고 이야기하는 것은 DB까지 분리되는 것을 의미함 (아래 이미지에서 육각형으로 표현)
- 결제, 주문중계을 떼어냄.
- IDC에서 AWS 클라우드 인프라로 이전 결정. 이때가 국내에 AWS가 막 들어오는 시점이고 개발자가 40명 정도 되었기 때문에 인프라만을 담당해줄 사람도 많지 않았음.
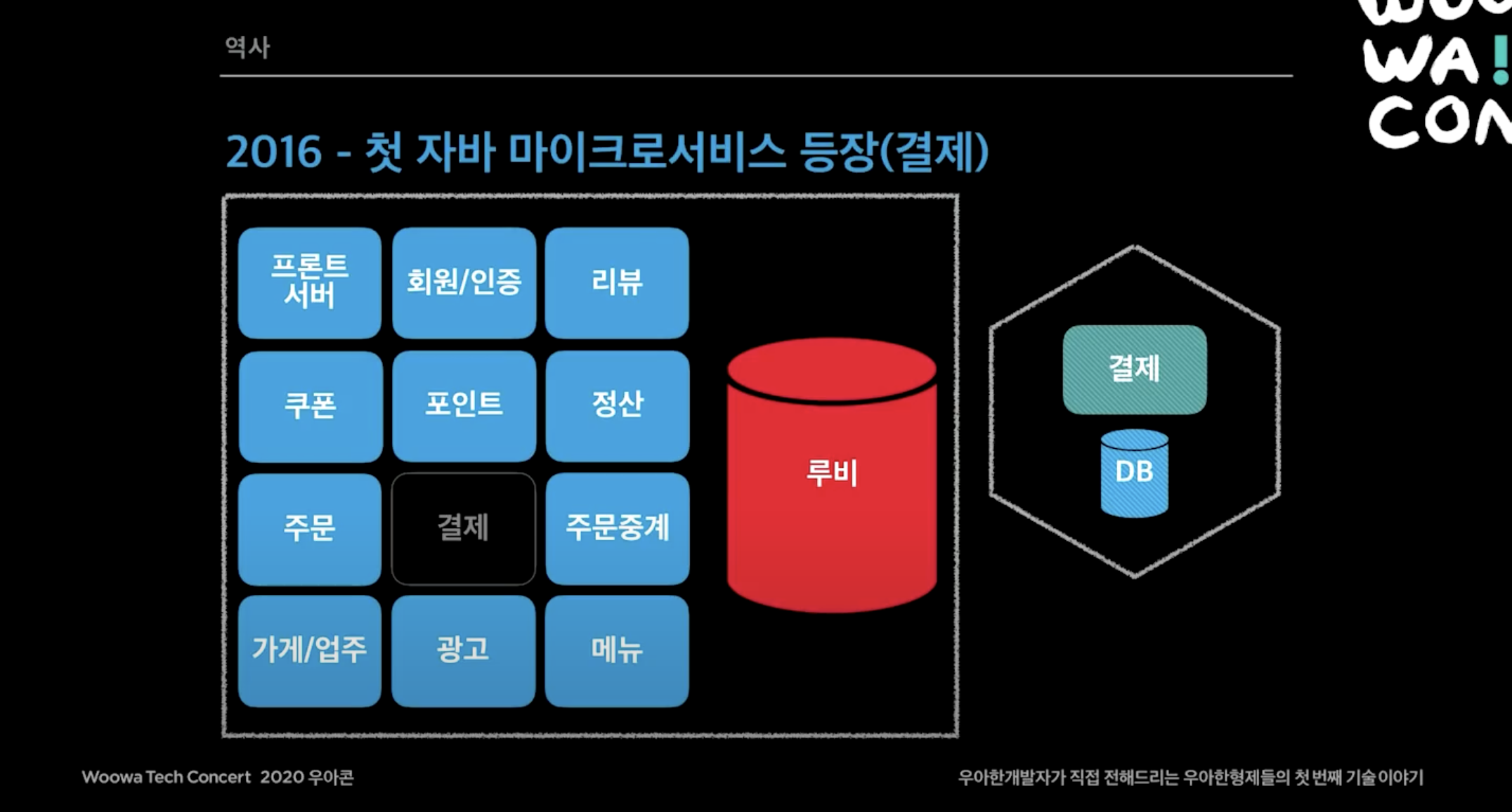
- 이때 DB는 MariaDB를 사용함.
- 그 당시 돈과 관련된건 클라우드에 올리지 못했어서 이때 결제 DB는 기존 IDC를 사용했음.
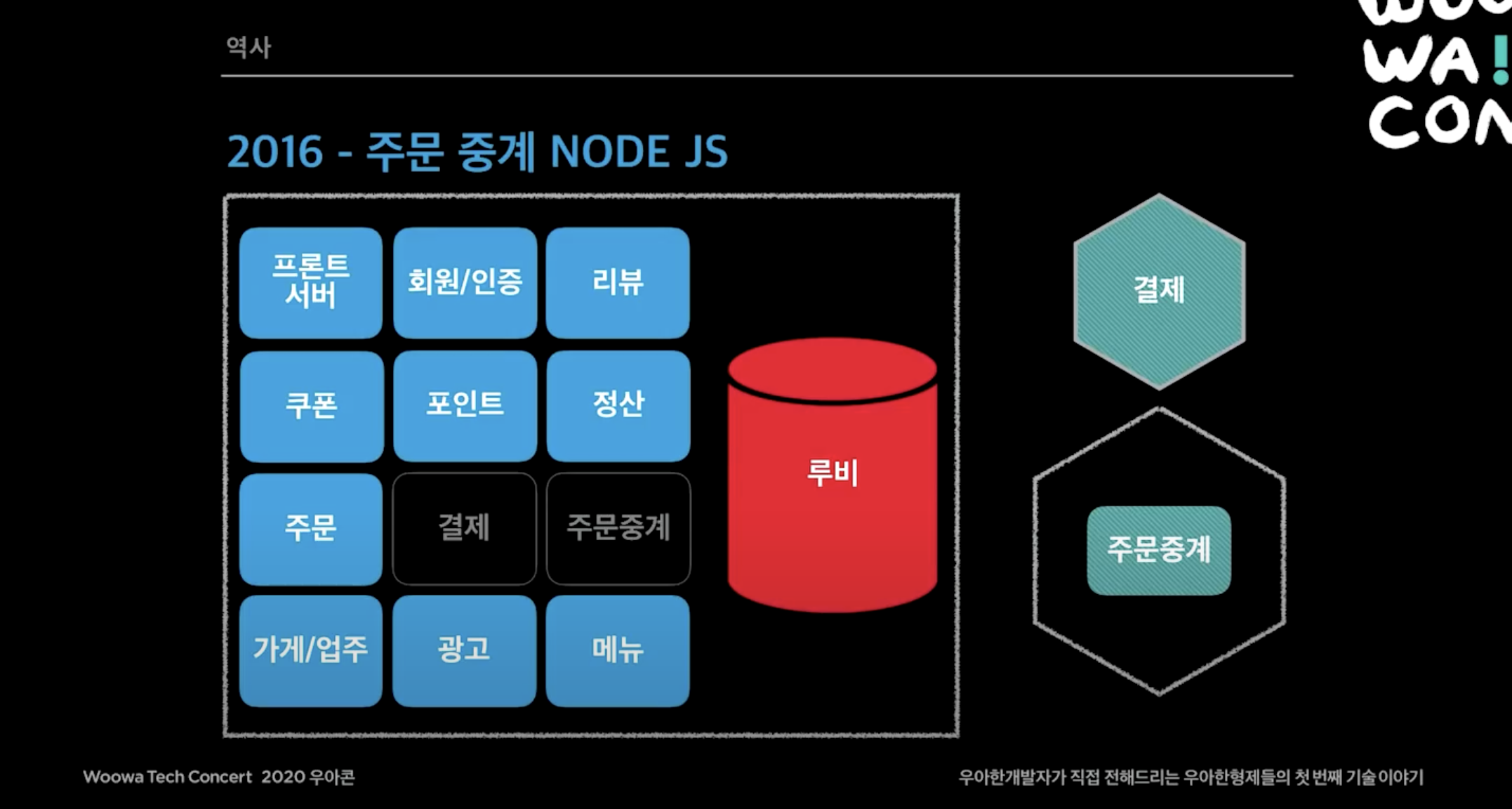
- 주문중계는 주문하면 사장님들은 앱, pc, 단말기에서 주문을 받을 수 있는데 중간에서 이 주문을 포워딩해주는 게이트웨이 서비스인데, 이 당시는 nodejs를 썼지만 현재는 서비스가 복잡해지면서 지금은 java를 사용함.
- 치킨 마케팅에서 결제가 엄청 몰렸을 때 프론트, 주문 서버가 죽고 심지어 pg사까지 죽었는데, pg사도 어떻게 어떻게 장비를 수급해서 pg사도 장애를 대비하고 했었음.
2017년
- 하루 주문수 20만 돌파.
- 대 장애의 시대.
- 메뉴, 정산, 가게 목록 시스템이 독립함.
트래픽은 계속 느는데 전부 레거시라 토요일 오후 5시가 되면 긴장했다. 엔지니어가 장애나면 장애날 수 있지라고 생각할 수 있는데 이때 장애가 나면 전국민의 역적이 되었다. 사장님은 치킨을 준비하는데 장애가 나면 사람들은 전화주문을 안하고 요기요 가면 요기요가 트래픽으로 죽고, 배달통도 죽고한다. 몇몇 사장님들이 영업사원에게 있는말 없는말 다한다. 정말 생존을 위해 마이크로서비스를 해야했다.
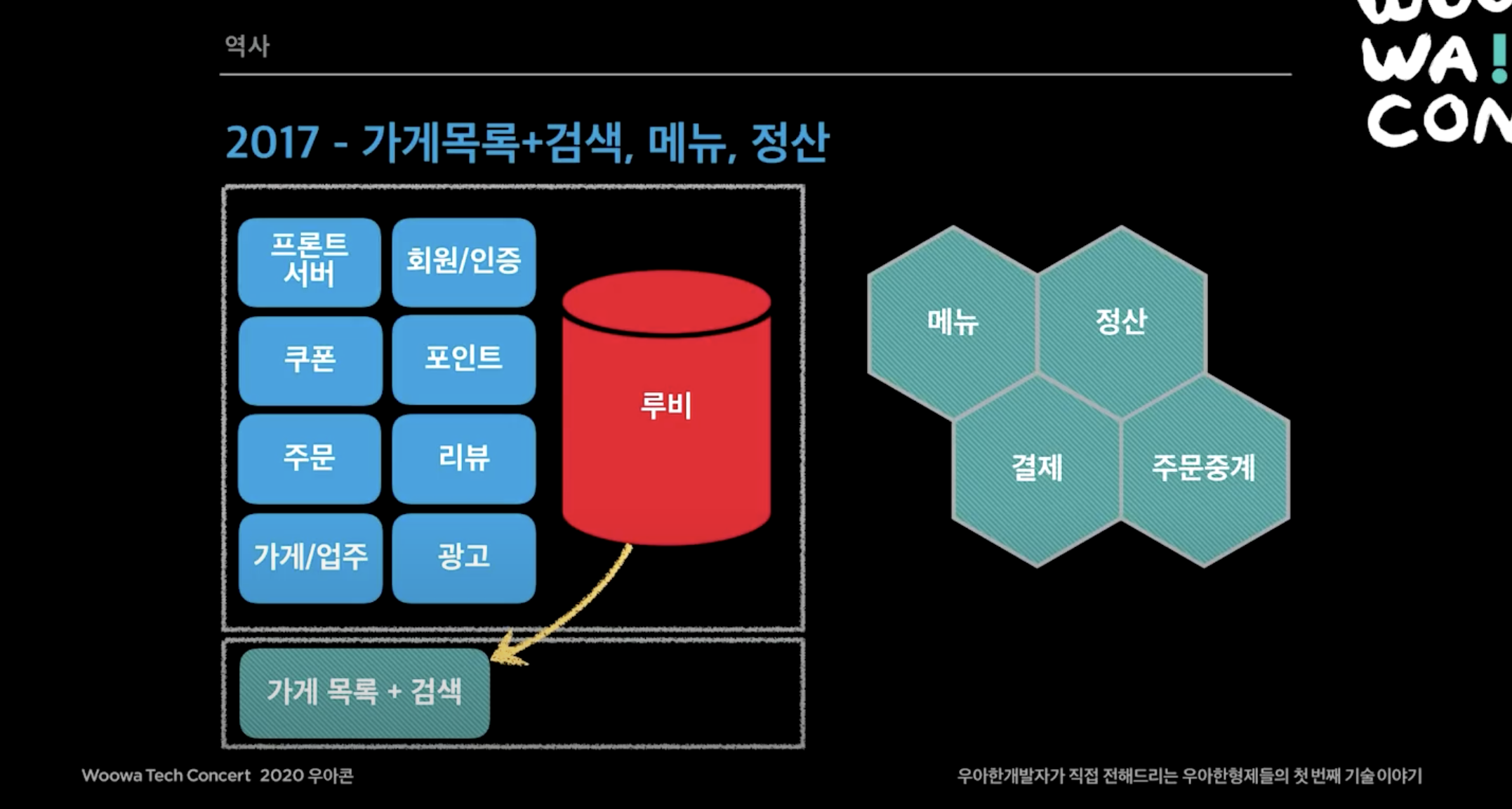 광고와 검색이 하나의 프로젝트로 되어있었는데 각 목록이랑 검색을 루비 DB에서 분리하고 Elasticsearch로 떼어내어, 루비 DB에 가는 부하를 줄였다.
광고와 검색이 하나의 프로젝트로 되어있었는데 각 목록이랑 검색을 루비 DB에서 분리하고 Elasticsearch로 떼어내어, 루비 DB에 가는 부하를 줄였다.
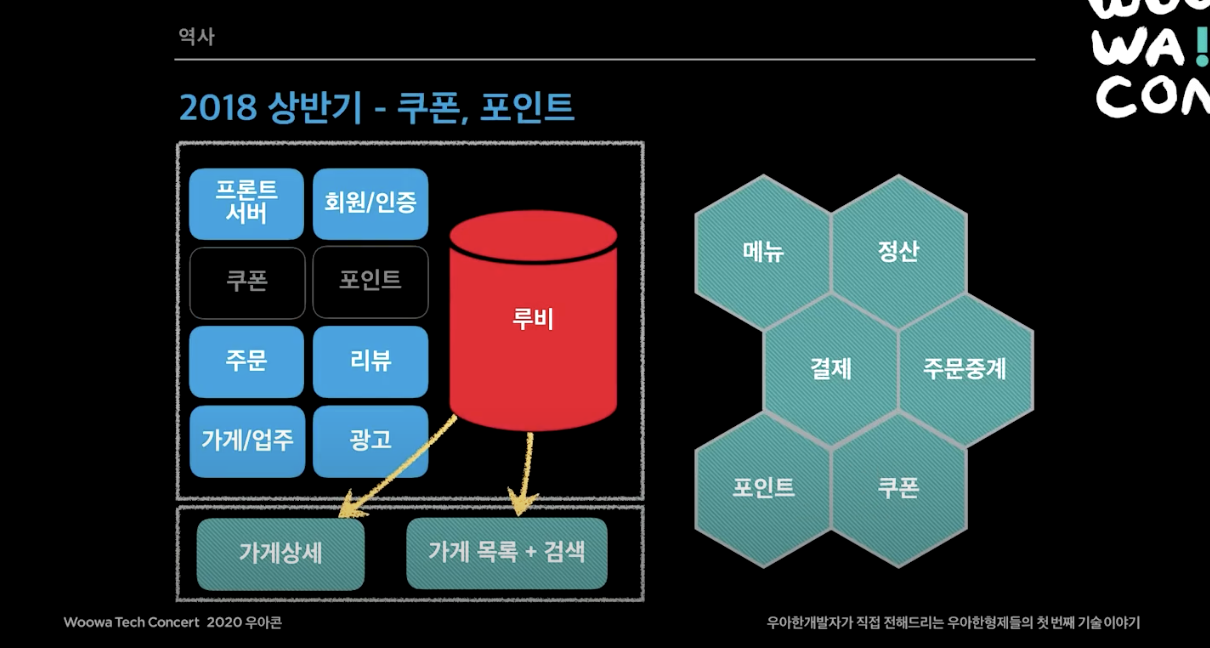
2018년 상반기
- 배민은 시스템 안정성이 가장 중요하다고 전사적으로 결정함.
- N 광고 기획을 미루고 장애대응 TF가 창설됨. 이 때까지만 한 가게는 하나의 광고만 가능했는데, 하나의 가게가 여러개의 광고를 띄울 수 있는 기획을 미루고 시스템 안정성을 먼저 챙기자는 의사결정을 할만큼 이 문제에 대한 공감대가 회사 전체에 있었음.
- 주요 장애포인트였던 가게 상세를 재개발에 들어감.
- 오프라인 모드 적용. 서버가 죽었을 때 앱만 동작하게 끔 개발됨. AWS가 죽었을 때 효과를 봄. ( 오프라인 모드 블로그 글 )
- 가게상세, 쿠폰, 포인트도 루비 DB에서 떼어냄
2018년 하반기
- 주문, 리뷰를 루비 DB에서 분리
- 레거시 3대장
- 주문: 데이터 지분 1위, 비즈니스 연관도 1위, 하루에 100만 데이터가 쌓임.
- 가게/업주: 시스템 연관도 1위. 모든 시스템에서 가게/업주 데이터는 전부 필요함.
- 광고: 프로시저 사용 1위. 걷어내기 쉽지 않음.
주문
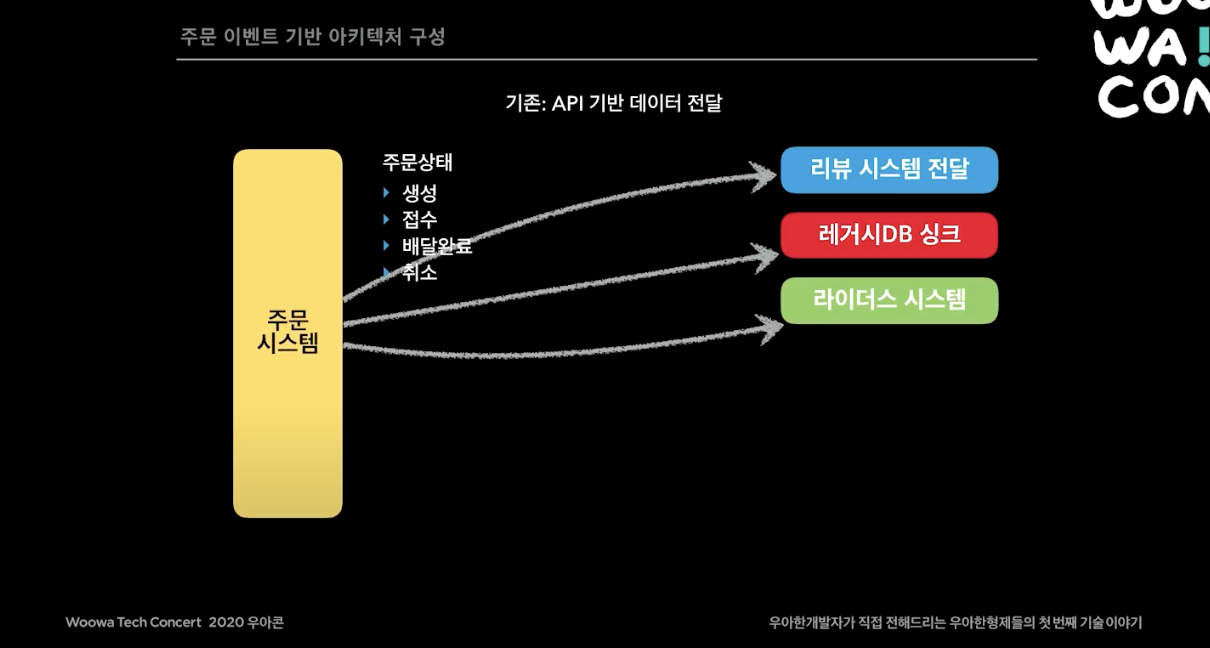 기존의 주문 시스템은 API 기반으로 데이터를 전달하고 있었다. 주문이 생성, 접수, 배달완료, 취소가 되는동안, 굉장히 많은 외부 API를 호출하고 있었다. 예를들어 주문하면 이벤트가 발생하면 사장님이 접수도 해야하고, 라이더스 시스템에도 알림이 가야하고, 리뷰 앱 푸시도 나가야하고, 레거시 DB와도 동기화를 시켜줘야한다. 이 모든게 API로 연동되고 있었다. 이 시스템의 문제는 예를들어 리뷰 시스템에 장애가 나서 API가 끊기면 주문 시스템도 500에러가 나거나 타임아웃이 나면서 영향을 받는다는 것이다.
기존의 주문 시스템은 API 기반으로 데이터를 전달하고 있었다. 주문이 생성, 접수, 배달완료, 취소가 되는동안, 굉장히 많은 외부 API를 호출하고 있었다. 예를들어 주문하면 이벤트가 발생하면 사장님이 접수도 해야하고, 라이더스 시스템에도 알림이 가야하고, 리뷰 앱 푸시도 나가야하고, 레거시 DB와도 동기화를 시켜줘야한다. 이 모든게 API로 연동되고 있었다. 이 시스템의 문제는 예를들어 리뷰 시스템에 장애가 나서 API가 끊기면 주문 시스템도 500에러가 나거나 타임아웃이 나면서 영향을 받는다는 것이다.
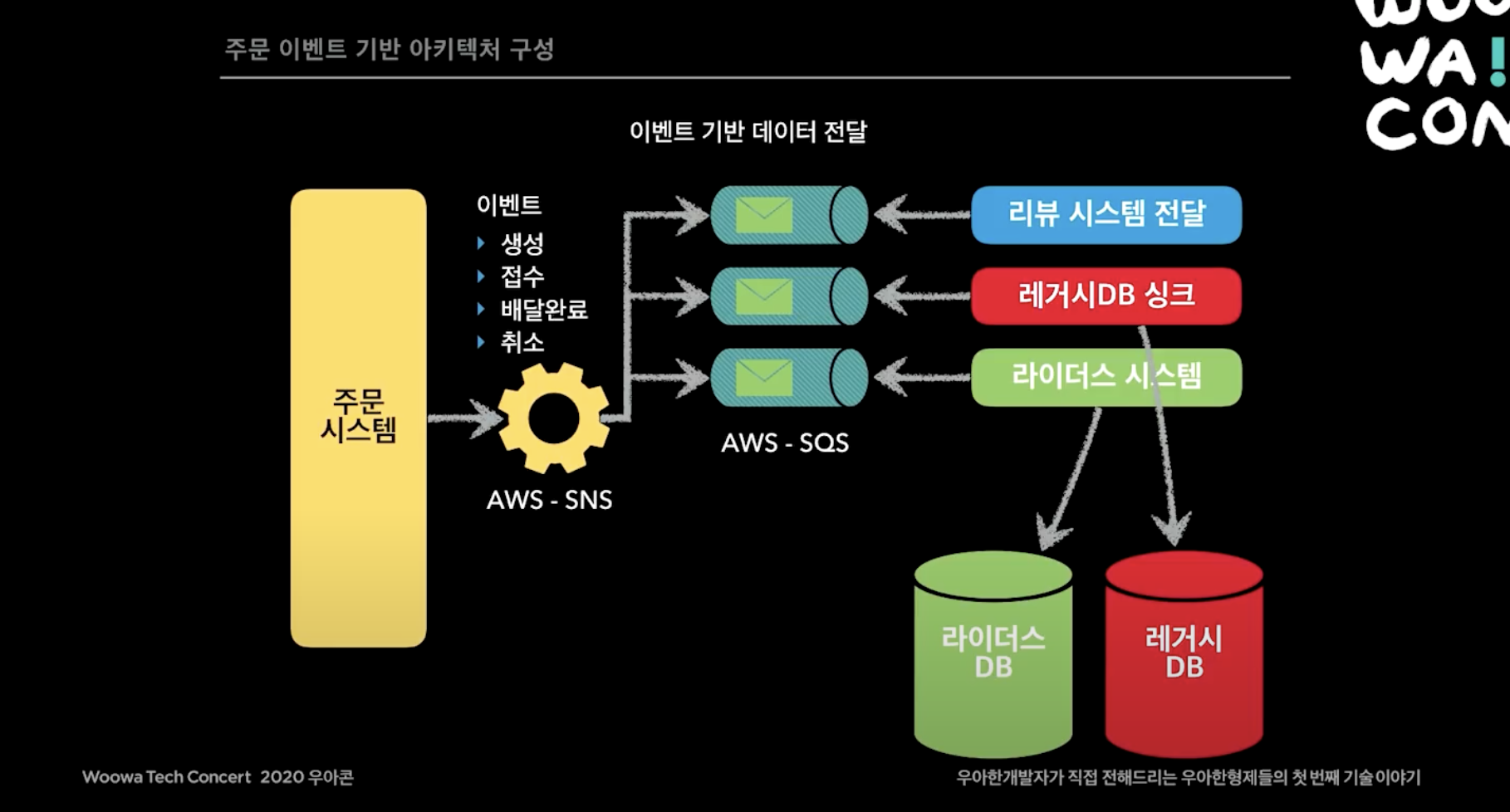 그래서 주문 시스템에 대해 이벤트 기반의 마이크로 서비스 아키텍처를 고민하기 시작했다. 앞으로 주문시스템은 이벤트만 발행하고 다른 시스템이 원하면 주문 이벤트를 subscription 해서 원하는 데이터를 가져오면서 완전히 시스템을 분리했다.
그래서 주문 시스템에 대해 이벤트 기반의 마이크로 서비스 아키텍처를 고민하기 시작했다. 앞으로 주문시스템은 이벤트만 발행하고 다른 시스템이 원하면 주문 이벤트를 subscription 해서 원하는 데이터를 가져오면서 완전히 시스템을 분리했다.
그 당시에는 AWS SNS, SQS 노하우가 있어서, 주문 시스템이 SNS topic에 이벤트를 publish 하면 이 topic은 다양한 subscriber(SQS, Lambda 등)에게 전달된다. 리뷰 시스템이나 레거시 DB나 라이더스 시스템에서 SQS를 만들고 이벤트를 consume하는 방식으로 바꿨다. 리뷰시스템이 죽어도 주문 시스템은 아무 연관이 없다. 거기다가 리뷰 시스템 죽었다가 살아나면 기존 API 방식에서는 그 API가 날라가는데 이런 이벤트 기반 시스템에서는 리뷰 시스템이 살아나는 순간 AWS SQS에 쌓여있는 이벤트를 다시 consume 해서 fcm를 보내는 등의 작업을 다시 보낼 수 있다.
무슨 새로운 서비스 만드는데 주문의 데이터가 필요할 때, 주문 시스템에서는 할게 없어진다. 새로운 시스템에서 필요한 SQS를 만들고 SNS에 연결한 다음에 시스템에서 SQS에 쌓이는 데이터를 가져와 쓰면된다. 이렇게 되면서 장애가 급격하게 줄어들게 된다.
가게/업주
이처럼 배민 대부분 비즈니스 로직이 루비 DB에 있는 가게와 광고 데이터를 보고 있었다.
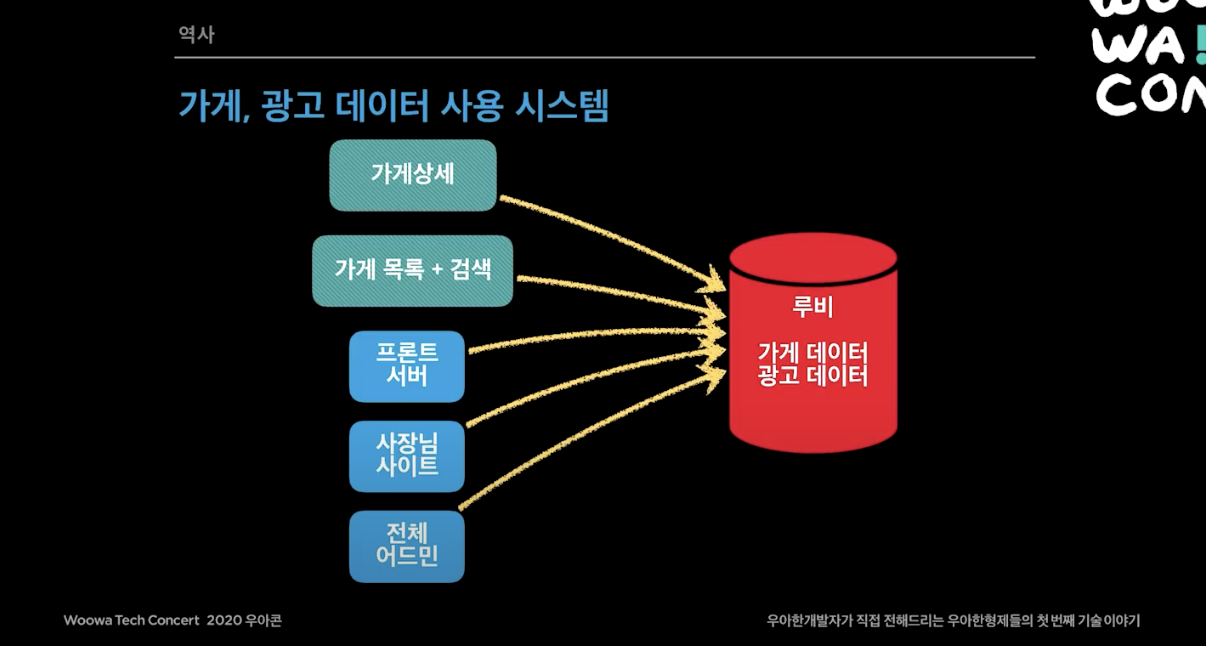
가게/업주 개선 작업은 비즈니스를 몇달간 멈춰야하는 정도였다. 가게 테이블 안에 컬럼이 100개 가까이 되는 테이블도 있었다. 기술적으로 마이크로 서비스로 갈려면 프로젝트를 34달 중단시켜야 하지만 회사는 N 광고 비즈니스(하나의 가게가 여러 광고를 할 수 있도록 하는 비즈니스)를 해야했다. 이걸 설득하기 되게 힘들었지만 해냈고 34달 동안 레거시를 없애는데 집중하게 개발팀을 도와주자고 의사결정이 진행되었다. 이를 먼데이 프로젝트라고 부른다.
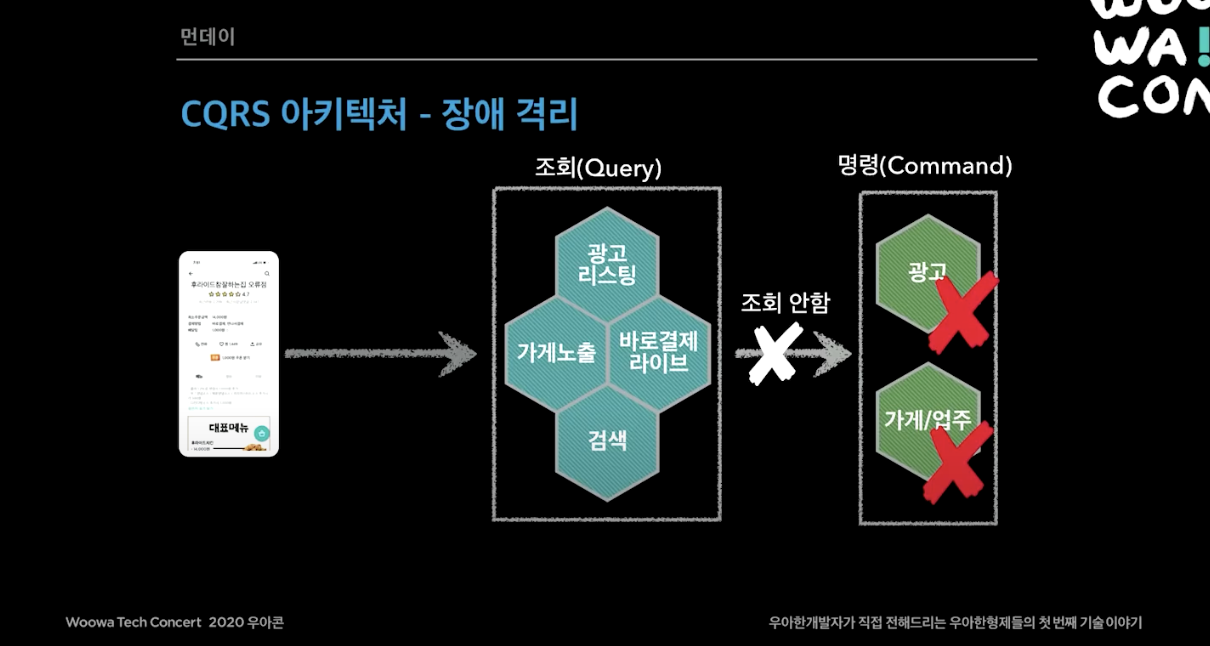
2018년 12월에 먼데이 프로젝트가 시작되었다. 먼저 가게 상세를 가게 노출(가게 목록, 상세) 시스템으로 변경하기로 했다. 마이크로 서비스를 공부하다보면, CQRS의 쿼리 모델이라는게 있다. 가게 노출 시스템의 핵심 역할은 서비스 조회용 가게 데이터를 가지고 있는 쿼리 모델을 만드는 것이다. 두번째로 가게 목록과 검색이 하나로 되어 있었는데, 이것을 광고용 시스템과 검색용 시스템으로 명확히 분리했다.
그렇게 처음으로 생각할 수 있는 구조는 이렇게 가게/업주와 광고 시스템을 떼어내서 마이크로 서비스로 만들고 다른 시스템에서 API로 불러오도록 하는 것이다.
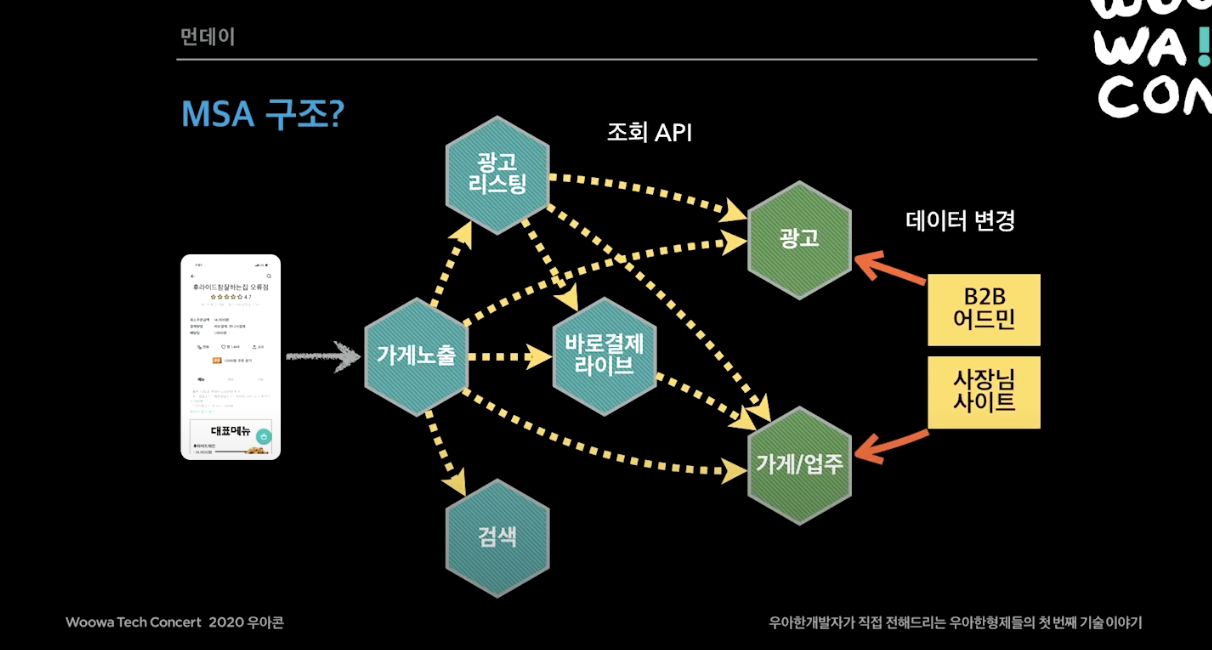 하지만 이렇게 단순히 API 조회 형식으로 하면 두가지 문제가 존재한다.
하지만 이렇게 단순히 API 조회 형식으로 하면 두가지 문제가 존재한다.
- 이유 1. 장애 전파가 일어날 수 있다.
- 이유 2. 대용량 트래픽이 다른 시스템으로 전파될 수 있다. 배민 트래픽이 계속 늘어나고 있었고, 이벤트를 많이했다. 대량의 트래픽이 순간적으로 몰리고 이 트래픽이 모든 시스템에 다 퍼진다. 가게 노출이나 광고 리스팅은 대용량 트레픽을 맞도록 설계할 수 있지만 광고나 가게/업주 시스템은 정확하고 안정적으로 운영해야했다.
먼데이 프로젝트의 아키텍처 고려사항에서 중요한 성능, 장애격리, 데이터 동기화가 있었다.
성능
- 대용량 트래픽 대응 (점심, 저녁, 이벤트 때 몰리는 트래픽을 대응할 수 있어야 함)
- 메인, 가게 리스트, 가게 상세 API 는 초당 15000회 호출을 감당해야함.
- 모든 시스템이 대용량 트래픽을 감당하기는 어려움.
장애 격리
- 가게, 광고 같은 내부 서비스나 DB에 장애가 발생해도 고객 서비스를 유지하고 주문도 가능해야함.
데이터 동기화
- 데이터가 분산되어있는데 이 데이터들이 동기화 되어야함.
성능, 장애격리 문제대응
먼저 배달의 민족 전체 시스템을 CQRS 아키텍처로 설계했다. CQRS(Command and Query Responsibility Segregation)은 핵심 비즈니스 명령 (Command) 서비스와 조회(Query) 중심의 사용자 서비스를 철저하게 분리하는 설계방식을 의미한다.
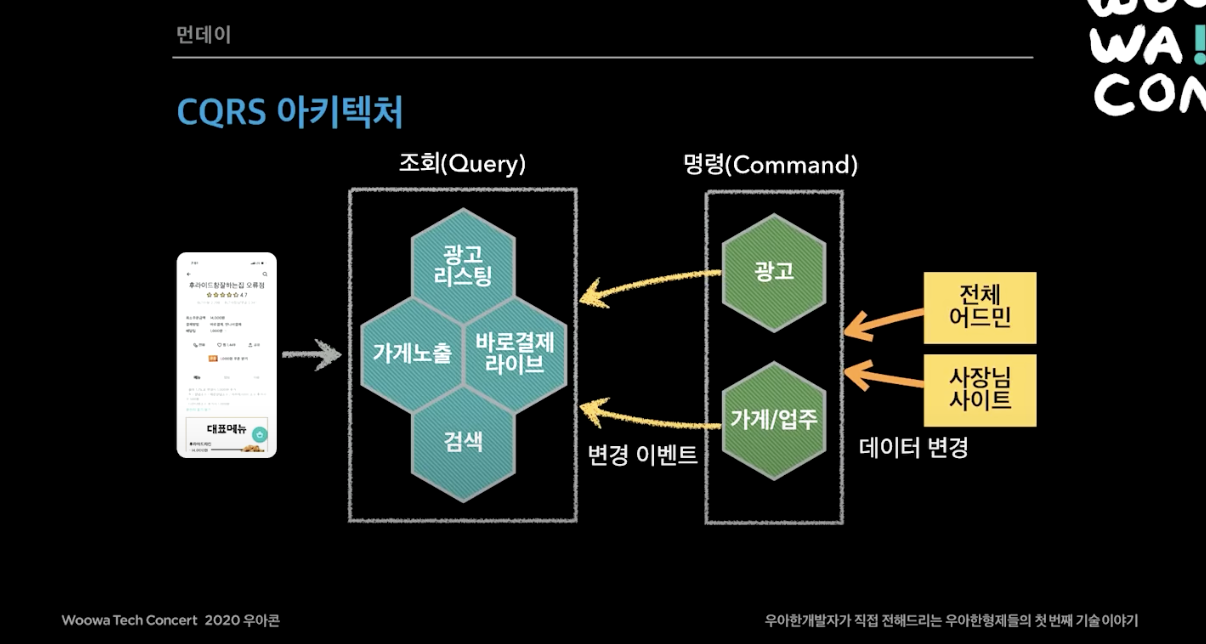
사장님 사이트에서 데이터를 변경하고 이벤트를 발행하면 SNS/SQS 모델을 통해 이벤트가 전파되며 각 서비스의 DB를 업데이트를 한다. 그 당시 AWS Managed Kafka 서비스가 없었고 AWS SNS/SQS 노하우가 많이 있어서 AWS SNS/SQS를 사용했다.
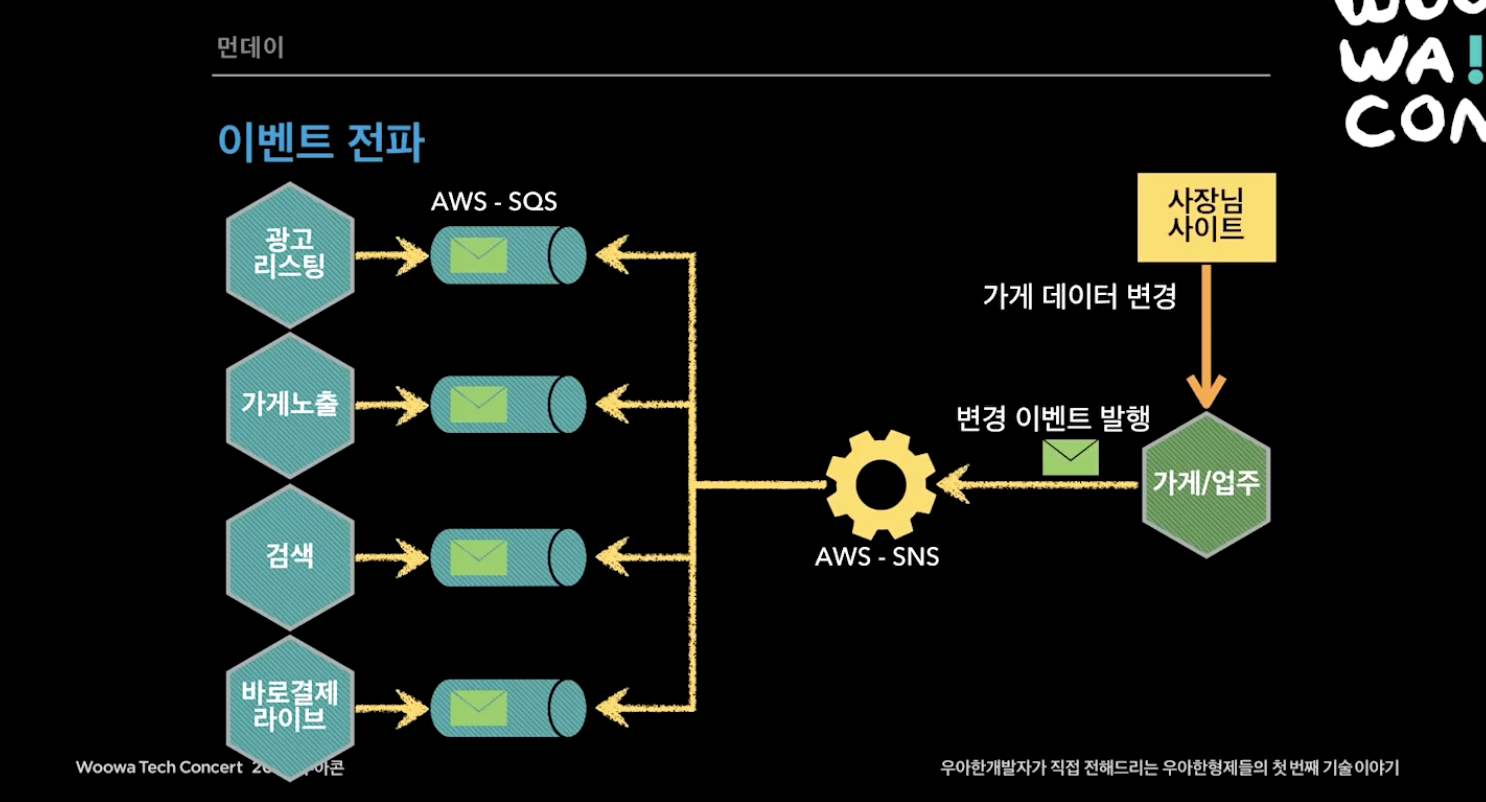
이벤트 전파와 동기화는 다음의 규칙을 지키는 방식으로 진행했다.
규칙 1. Eventually Consistency (최종적 일관성) 을 맞추었다. 데이터는 언젠가 싱크가 다 맞추어지도록 설계한 것인데, 늦어도 1~3초에는 데이터 싱크가 다 맞춰졌다.
규칙 2. 한 서비스에서 문제 발생하면 해당 서비스의 이벤트만 재발행하도록 했다. 여기서 이벤트 발행하는 방식을 이벤트 메세지 안에 가게 모든 데이터를 보내거나, 변경된 데이터만 보내거나 할 수 있는데 그 방식을 안쓰고 zero-payload 방식을 사용했다. zero-payload 방식은 이벤트 식별자(ex. 가게 id)와 최소한의 정보만 발행하고 이벤트를 받은 시점에 조회 API로 필요한 데이터를 조회해서 저장한다. 테이블의 전체 데이터를 전부 보내는 것은 현실적으로 힘들고, 변경 될 때마다 해당 데이터를 업데이트 해줘야하는 것도 따로 공수가 드는 일이라 id만 보내고 따로 조회하는 방식을 사용했다.
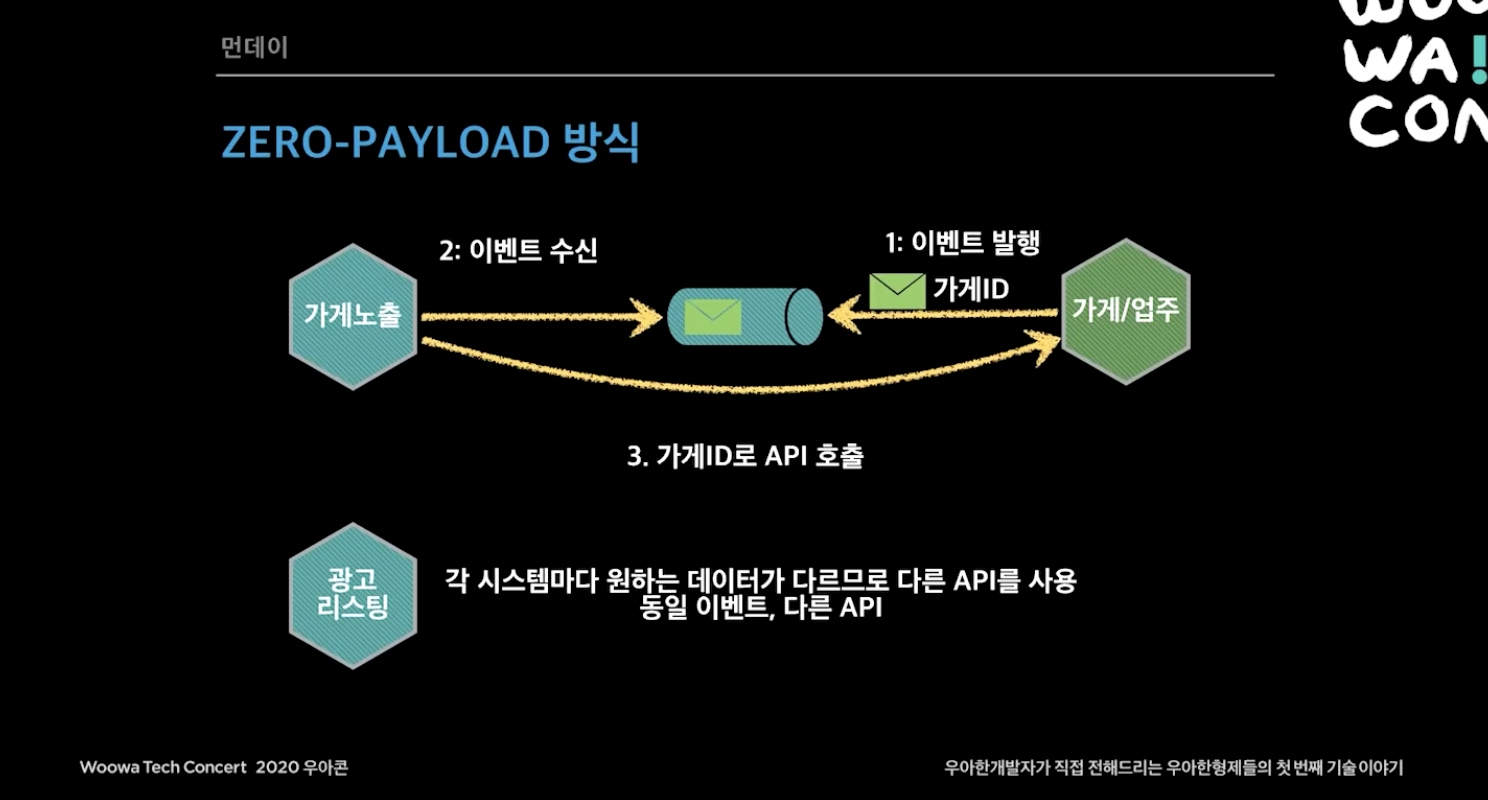
규칙 3. 최소 데이터 보관 원칙을 지킨다. 이는 각 시스템은 모든 데이터를 보관하면 안되고 서비스에 꼭 필요한 최소한의 데이터만 보관한다는 것인데, 이것이 물리적인 의존관계는 없지만 데이터를 가지고 있으면 논리적인 의존관계가 생긴다. 그래서 가게업주에서 데이터를 바꾸면, 데이터를 전부 다 봐야하는 문제가 생길 수 있기 때문에 각 시스템은 최소한의 데이터를 보관하도록 한다.
규칙 4. 서비스 자체 데이터 저장소를 사용하고 이를 이벤트 기반으로 동기화한다 고성능이 필요한 조회 중심의 서비스에서는 가게노출에서는 DynamoDB, MongoDB(NoSQL), Redis(Cache)를 사용하고, 광고리스팅과 같은 검색 서비스에서는 Elasticsearch를 쓴다. 반대로 안정성이 중요한 명령형 중심의 서비스에서는 광고와 가게/업주 서비스에서 Aurora DB(RDB)를 사용했다. 이를 polyglot persistence 라고하는데, 각 시스템에 최적화 된 데이터베이스를 선택할 수 있다는 것이다. 가게/업주는 관계형 DB를 사용하고 이벤트를 보내면, 성능이 중요한 곳들은 DynamoDB Redis 사용하고, 검색을 주로 하는 곳이면 Elasticsearch를 사용하도록 했다.
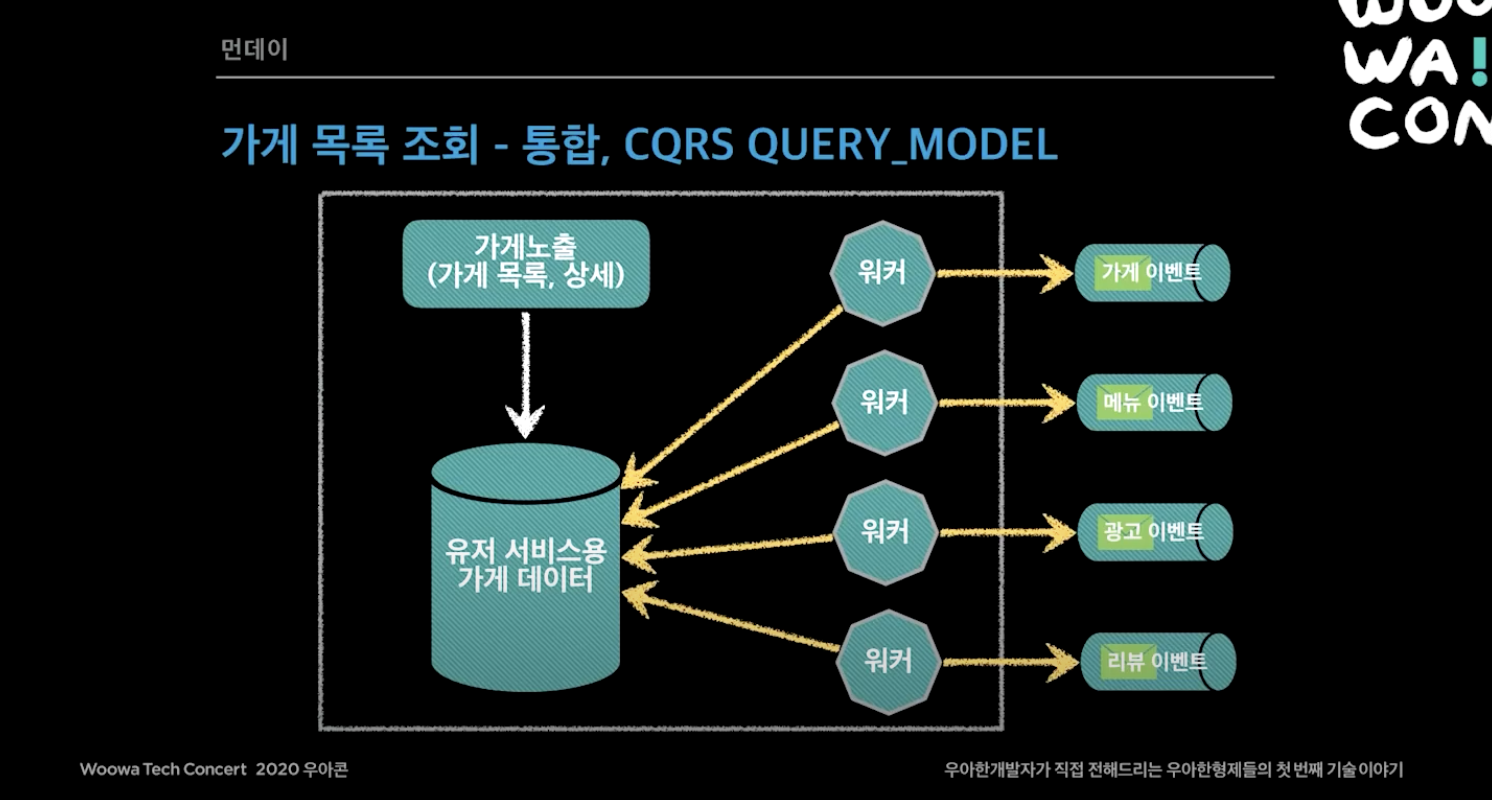
그렇게 CQRS 아키텍처를 통해서 성능을 보장하고 장애격리를 할 수 있게 되었다. 페이지 예시로 먼저 가게 목록 조회 페이지를 보자. 가게 노출 시스템이 CQRS QUERY MODEL로 되어 있는데, 가게 목록 화면을 보면 가게정보, 광고 등 보여줘야하는 데이터가 엄청 많다. 이를 빠르게 조회하기 위해, 여러 시스템에서 가게 노출 시스템으로 이벤트가 오면 키를 가게 ID로 하고 값을 화면에 필요한 데이터를 flat 하게 만들어 저장해놓는다. 이런 방식으로 가게 데이터를 관리한다.
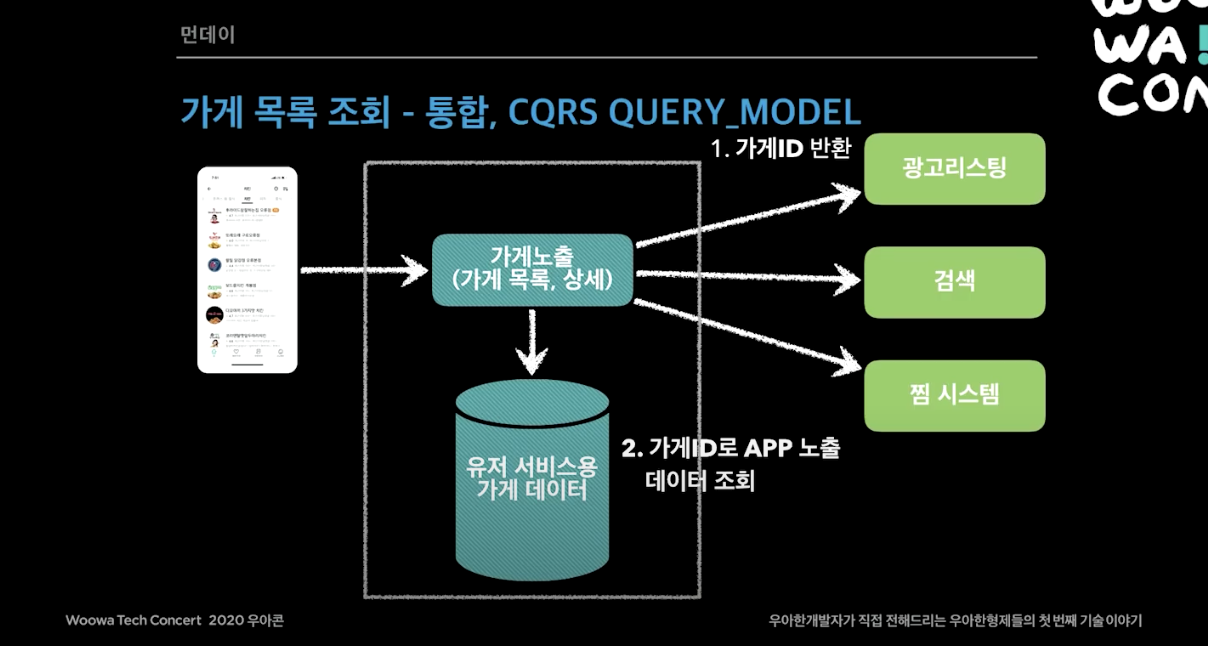
두번째 예시로 가게 상세 페이지에서는 3가지 시스템(바로결제 라이브, 쿠폰시스템, 유저 서비스용 가게 데이터)을 한번에 비동기 non-blocking로 조회하게끔 설계했다.
이렇게 CQRS 아키텍처를 통해서 성능을 보장하고 장애격리를 할 수 있게 되었다. 각 시스템이 내부에 필요한 데이터를 보관하고, 내부 서비스(ex. 광고, 검색)의 모든 변경 내역이 이벤트로 전달되며, 장애시 데이터 싱크가 늦어져도 고객 서비스가 가능했다.
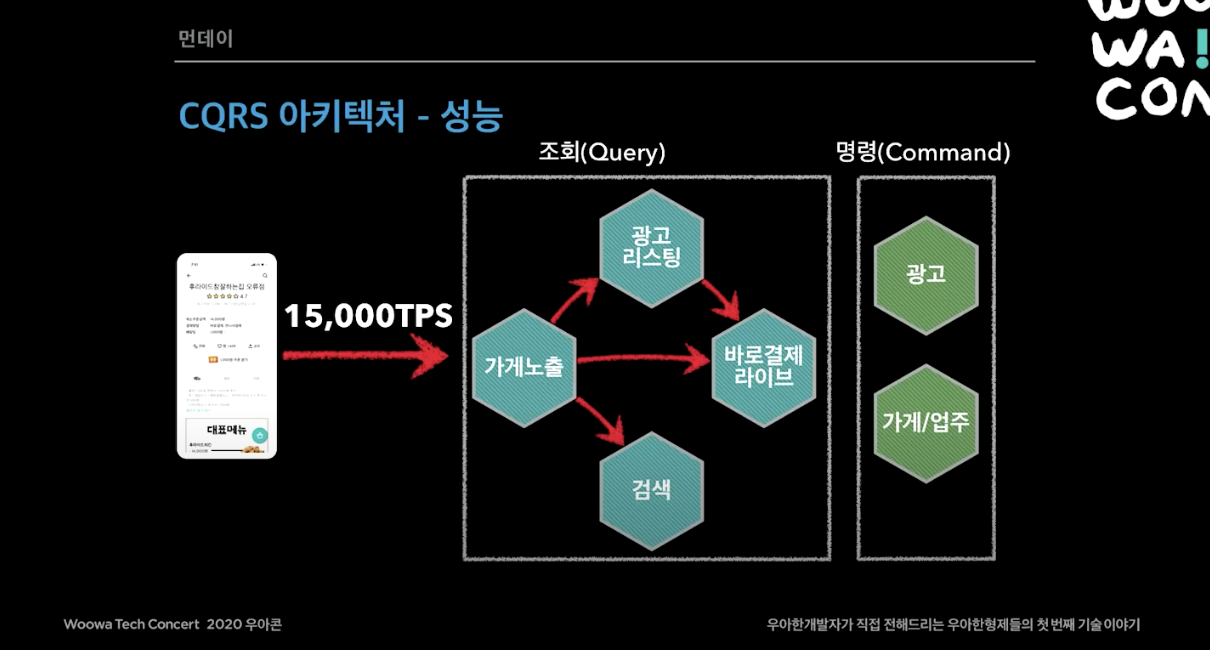
데이터 동기화 문제대응
특정 서비스에서 장애가 나면 이벤트를 재발행 해주고 가끔 큐 장애가 발생하면 다른 서비스의 API를 전부 가져와서 사용하거나, 최근 업데이트 데이터를 가져오기 위한 API를 부분적으로 제공한다. 그 외에도 적극적으로 캐시를 사용하고 서킷 브레이커도 사용하도 비동기 non-blocking 시스템도 적용했다.
요약
- 배달의민족 시스템은 거대한 CQRS
- 성능이 중요한 외부 시스템과 비즈니스 명령이 많은 외부 시스템으로 분리
- 이벤트 발행을 통한 Eventually Consistency
- 각 시스템은 API 또는 이벤트 방식으로 연동함
마이크로 서비스는 규모의 경제가 되었을 때 하는게 맞다. 시스템규모, 트래픽 규모, 사람도 많아야한다. 데이터 싱크하고 맞추면 비용이 10배 정도 더 든다. 그런것들을 상쇄하고 남을만큼 가치가 있을 때 하는게 좋다.
당근마켓
[Tech Seminar] 당근마켓 성장과 개발 스택의 변화 발표영상 을 참고하여 아래 글을 작성했다.
2015.12월
- Ruby on Rails로 개발함. 창업자들이 회사에서 써본적은 없었지만 rails에 관심이 있었음.
- AWS EC2에 올림. 이때까지만 해도 AWS를 많이 쓰지 않았는데, 개인적인 관심과 앞으로 많이 쓸 것 같다는 생각에 서버를 직접 구매하지 않고 AWS EC2에 직접 올림.
- 2년 동안은 이걸로 버틸 수 있었음.
2018.02월
- 이때까지만 해도 손으로 EC2를 띄우고 있었음.
- 전반적인 인프라 개선 작업 진행 (Terraform 도입, AWS VPC 등 개선)
2019.01월
- 50대가 넘는 서버에 배포할 때 copy, paste and run 방식으로는 한계가 있음. 서버 50대 ssh를 동시에 때리면 ssh 하나가 꼭 실패하고 서버 하나가 배포 실패했으니 전체가 롤백됨.
- 그래서 docker와 AWS ECS 도입함.
- 서버를 늘리고 copy and paste and run 방식으로 100만 mau 근처까진 버틸만했다. 2020년 현재 당근마켓은 서버가 60대이고 그 위에서 rails 컨테이너가 대략 2개씩 돌아감.
2019.06월
- 채팅서버를 분리하기로하고 go를 도입하기로함.
- 채팅이 트래픽 중에 많은 부분을 차지하고 있었고 일반적으로 웹서비스에서 db가 병목인데, 채팅 메세지가 전체 db의 1/3을 차지하고 있었음.
- 마침 회사에 go를 할 줄 아는 사람이 있었고 go로 채팅 서버를 분리하는 작업을 시작해서, db도 rdb에서 dynamodb로 바꾸면서 이 작업을 완료하는데 대략 7~8개월이 걸림. 1000만이 되어도 버틸 수 있다고 생각함.
2019.07월
- rail 개발자를 구하기 힘들어서 typescript 도입.
- 요즘 많이 사용하는 typescript를 도입해보자고 생각했고 마침 회사에 typescript를 잘하는 사람이 있었음.
2020년
- 최근에 트래픽이 급증하면서 많은 작업을 하고 있음.
- 인증도 rail로 붙어있던걸 떼고 db도 분리하려고 함
- 피드도 정렬을 rdb로 할 수 없어서 db를 분리하려고 함.
- 트래픽이 증가하면서 이외에도 지역서비스, 이미지 업로드, 감사로그, 머신러닝 추천 등에서도 플랫폼 분리 작업을 하고 있음.
- 이와 동시에 지역광고, 소상공인 정보도 모으고, 재난지원금, 마스크, 선거 등 지역과 관련된 새로운 서비스도 함께 개발 중임.
- 중고거래, 동네생활, 비매너 사용자 관리, 신고 운영개선 등 기존 서비스도 함께 개선 중임