긱뉴스의 최신 데이터 인프라 이해하기 영상이 데이터 인프라에 대한 전체적인 그림을 잡기에 좋은 내용들이 많아 정리해보고자 한다. 해당 영상은 A16Z에서 발행한 Emerging Architectures for Modern Data Infrastructure 글을 바탕으로 만들어졌다.
기본 개념과 단어 설명
아래 그림에 나오는 단어들을 전부 이해하는 것을 목표로 해보자. 그림을 간단히 요약하면 데이터 인프라 아키텍처는 크게 Sources, Ingestion and Transformation, Storage, Historical, Predictive, Output으로 구분할 수 있다. Sources에는 OTLP로 사용중인 AWS Aurora, 일자별로 RDS의 스냅샷 이 저장되어있는 S3, API 로그나 검색 서비스를 위해 사용하는 Elasticsearch 등이 모두 포함된다. 그리고 Ingestion and Transformation에는 ETL을 지원하여 데이터 파이프라인을 만들도록 도와주는 서비스들이 포함되어있다. 데이터를 추출해서 변환하고 어떤 곳에 적재하는 과정에서는 단순히 postgresql에 쿼리를 결과를 날린 후에 다른 곳에 저장하면 되지 않냐라고 할 수 있는데, 1억건 정도의 데이터도 한번에 조회하면 RDS의 메모리 사용량이 튀면서 쿼리가 지연되거나 실패하는 경우가 종종있다. 그래서 이러한 대용량의 데이터는 분산하여 처리하는 것이 중요한데 대표적으로 Hadoop이나 Spark를 사용한다. 그리고 특정 주기마다 workflow를 스케줄링 하기 위해 대표적으로 Airflow를 사용하고 반대로 실시간 데이터처리를 위해 Kafka나 AWS kinesis를 사용한다. 이런 처리를 한번 이상 거친 데이터들은 데이터 웨어하우스나 데이터레이크에 쌓이게되고 분석에 사용된다.
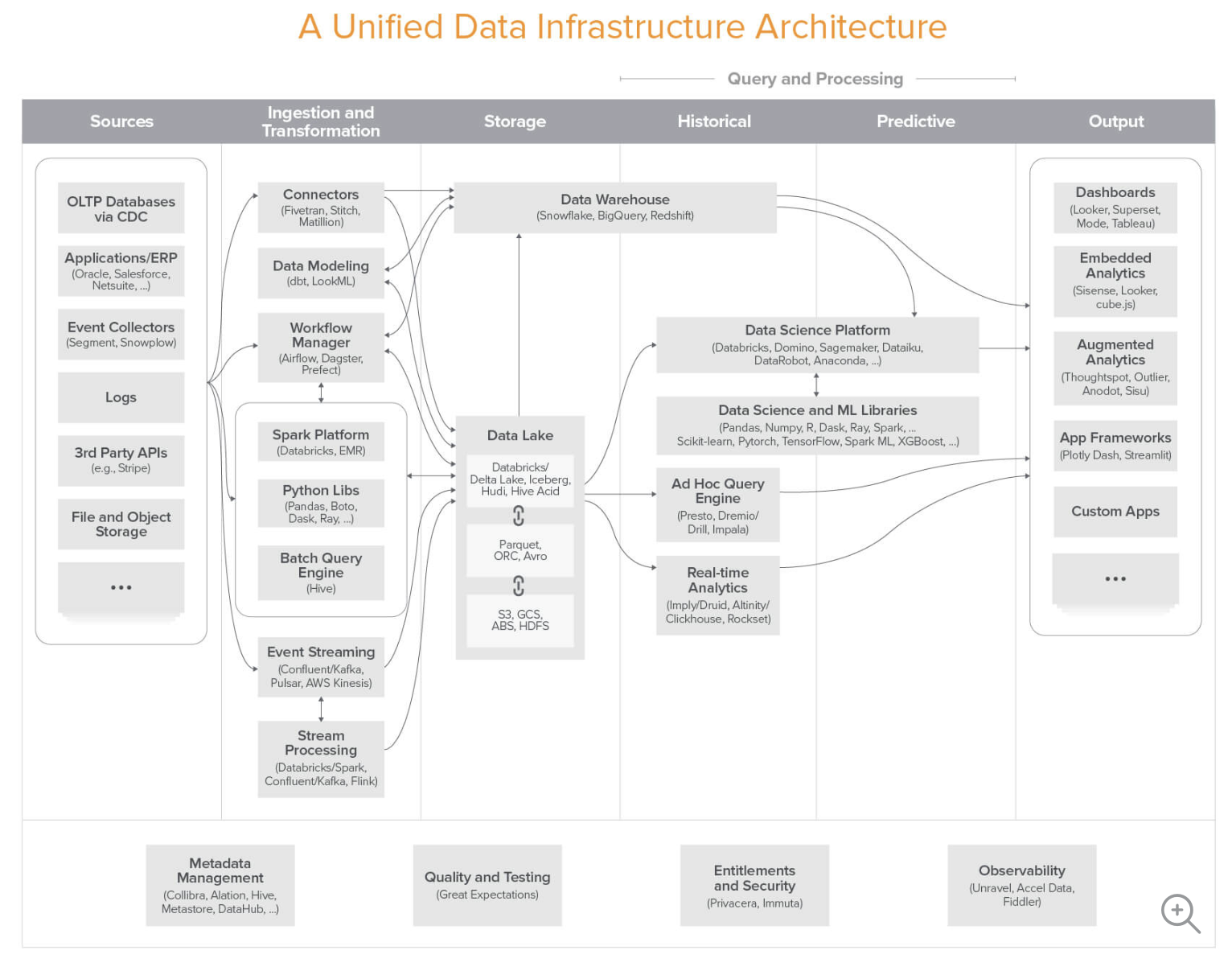 출처:
https://a16z.com/emerging-architectures-for-modern-data-infrastructure-2020/
출처:
https://a16z.com/emerging-architectures-for-modern-data-infrastructure-2020/
대용량 데이터가 저장될 수 있는 저장 공간, 대용량 데이터의 쿼리를 처리할 수 있는 컴퓨팅 리소스와 쿼리엔진 등 빅데이터에 최적화된 각각의 기술들이 필요하다. 데이터 인프라의 목적이 무엇일까? 첫번째는 비즈니스 리더들의 의사결정을 도와주는 Analytic Systems을 구축하는 것이고 두번째는 데이터의 도움을 받아 서비스를 향상 시키는 Operational Systems를 구축하는 것이다. 이 두가지의 목적을 달성하기 위한 데이터 인프라를 설계하기 위해 위의 A16Z의 블로그에서는 3가지 blueprint를 제공한다. 첫번째 blueprint는 모든 규모의 회사에 적용가능한 cloud-natvie 비즈니스 인텔리전스를 구축하는 아키텍처, 두번째 blueprint는 analytic과 operational을 모두 제공하는 multimodal data processing 아키텍처, 세번째 blueprint는 ML의 data transformation, training, inference를 지원하는 아키텍처이다. 자세한 그림은 위 그림 링크를 참고하자.
회사에서는 RDB나 NoSQL와 같이 다양한 데이터 소스로부터 데이터가 생성된다. 하지만 어느 순간 부터는 다양한 데이터 소스로부터 데이터를 저장하고 분석할 수 있는 데이터 웨어하우스의 필요성이 생기게된다. 데이터 웨어하우스 자체가 데이터를 분석하기 위해서 만든 것이다보니, 정규화되고 작은 여러개의 테이블로 쪼개져있던 운영계 DB와 달리 큰 하나의 테이블로 합치게 된다. 기존 운영계 시스템에서 빠른 데이터 업데이트가 필요한 것과 다르게 분석을 위해서 쉽게 데이터를 추출할 수 있게 만들기 때문에 데이터 스키마의 형태도 달라지게 된다. 여기서 production에서 사용하는 DB의 데이터를 옮겨야하는 상황이 오는데 이러한 작업을 ETL 과정이라고 한다. ETL은 extract, transform, load의 약자로 데이터를 추출하고, 정규화된 테이블에서 큰 하나의 테이블로 변환하고 데이터 웨어하우스에 적재하게된다. ETL은 큰 문제가 하나 있는데 추출과 변환 작업이 자동화 될 수 없고 변환하는 작업은 회사마다 다 다르기 때문에 자동화 시키기도 힘들고 수정하기도 힘들다. 그래서 변환을 먼저해서 적재 하는 것보다 변환에는 컴퓨팅 비용도 많이 나오고 저장공간은 저렴해지기 때문에 적재를 먼저하고 난 뒤에 다양한 용도로 변환 할 수 있으니까 ELT로 넘어가는 추세이기도하다.
그리고 아래 그림처럼 클라우드, 오픈소스, SaaS 비즈니스 모델로의 전환과 같은 소프트웨어 업계 전반에서 일어나고 있는 변화에 영향을 받아 데이터 인프라 아키텍처도 함께 변화하게 된다.
 출처:
https://a16z.com/emerging-architectures-for-modern-data-infrastructure-2020/
출처:
https://a16z.com/emerging-architectures-for-modern-data-infrastructure-2020/
Data sources
어떤 데이터들이 생성될 수 있을까?
- OLTP DB
- 회사 내부에서 생성되는 데이터(from ERP, CRM 등)
- 사용자가 생성하는 이벤트(ex. 어떤 웹페이지에서 얼마나 체류했는지, 어떤 버튼을 클릭했는지 등)
- 서버 로그 (ex. 웹서버, API 로그 등)
- 3rd Party APIs(ex. 아임포트, Vimeo 등 수많은 외부 SaaS 서비스들)
- 파일 또는 오브젝트 스토리지
OLTP Databases via CDC
OLTP(Online Transaction Processing)와 OLAP(Online Analytical Processing)는 저장된 데이터 사이즈, 처리 속도, 데이터 구조, 테이블 개수, 쿼리 복잡도의 기준으로 구분할 수 있다. OLTP가 필요한 서비스에서는 수많은 트랜잭션을 빠르게 처리를 해야하니, 정규화된 데이터 구조를 가진 경우가 많으며 분석에 필요한 복잡한 쿼리를 되도록 날리지 않는다. 여기서 CDC라는 개념이 등장하는데 change data capture의 약자로 OLTP에서 일어나는 추가, 업데이트 되면서 데이터의 변경이 있을 때마다 외부 DB에 복사하는 기술이다. OLTP DB는 트랜잭션을 기록하는데 최적화 되어있고 그 데이터를 다른 곳에서 사용하는데는 한계가 있다. 이를 이용하여 OLTP의 변경 분을 OLAP DB와 같은 다른 DB에 옮기는 것을 CDC라고 한다. CDC를 통해서 OLTP의 변경분을 OLAP로 옮겨서 처리할 수 있게된다.
Event Collector
웹 또는 앱 내에서 발생하는 사용자 이벤트를 수집하고 분석할 수 있다. 여기에 Google Analytics , Facebook Pixel, Amplitude, Braze, Segment 등의 툴이 사용될 수 있는데 특히 Segment는 customer data platform(CDP)의 대표적인 서비스로 앱 또는 웹에서 생성되는 이벤트를 Segment 서버로 전송하고, 해당 이벤트를 GA, Pixel 등에서 사용할 수 있는 형태로 데이터를 변환하여 전송할 수 있다. 또한 이벤트 데이터를 Segment 자체 서버에 저장하거나, 다른 데이터 웨어하우스(ex. Redshift, Postgres, BigQuery, Snowflake 등)로 전송할 수도 있다. Segment가 기능은 더 많지만 너무 비싸다고 생각될 때는 오픈소스들을 고려해볼 수도 있고 오픈소스로 제공된 CDP로는 대표적으로 snowplow 와 rudderstack 등이 있다.
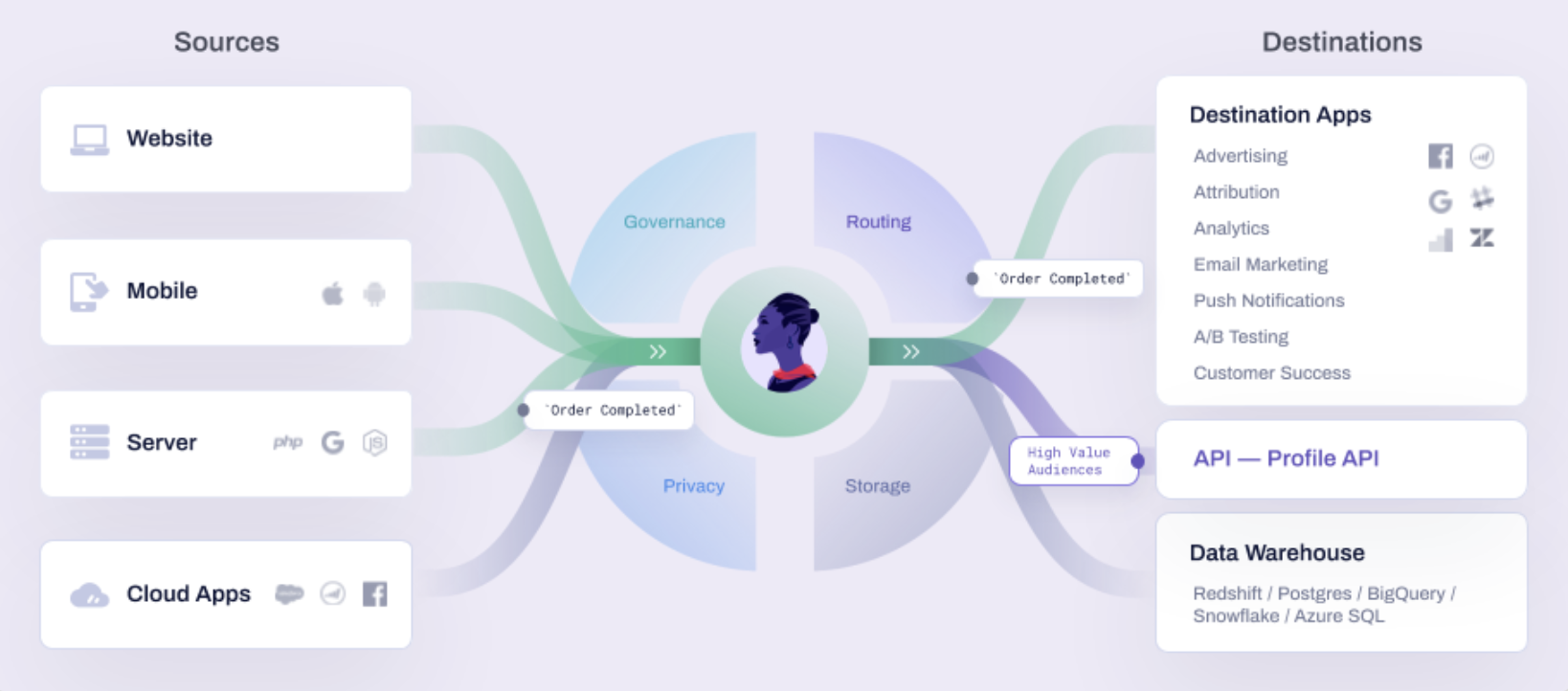 출처:
How Segment Work
출처:
How Segment Work
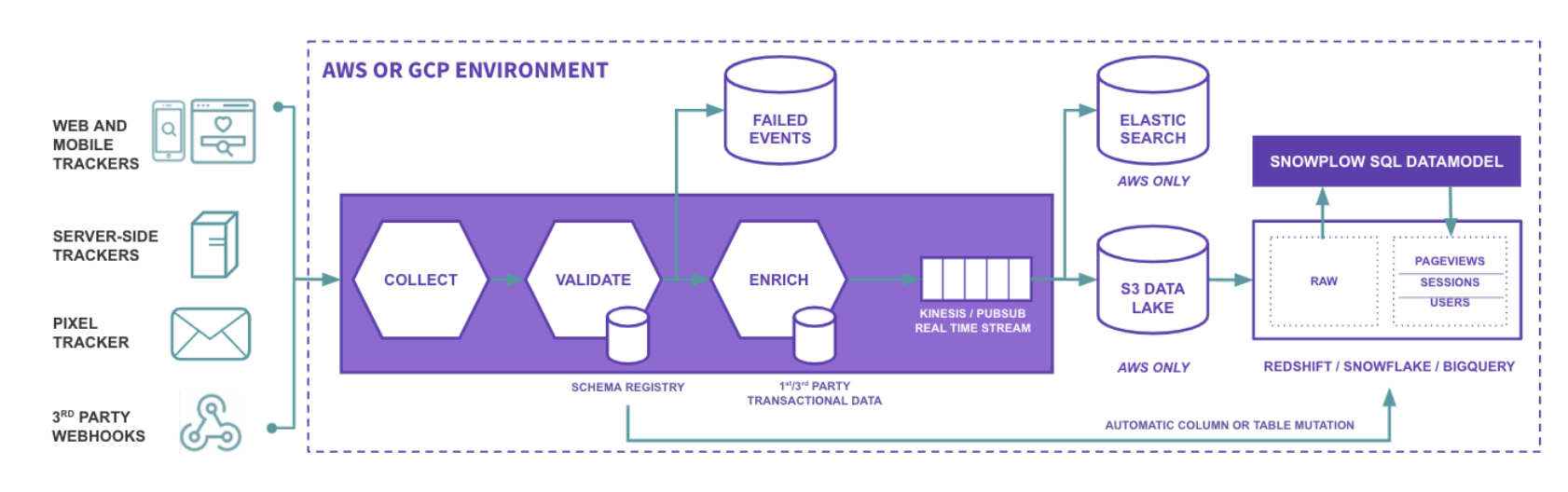 출처:
Snowplow technology 101
출처:
Snowplow technology 101
Ingestion and Transformation
Connector
대표적인 ETL 파이프라인 도구로 Fivetran, Matillion, Stitch 가 있다. 데이터 소스에서 데이터를 추출하여 타겟 DB로 이동하는 것이 메인기능이지만 데이터를 변환하여 분석이 가능한 형태의 스키마를 만들어 주거나, Tablueau나 Looker같은 BI툴과도 연동할 수 있다. 이 과정을 더 저렴하고 효율적으로 하는 싸움이다. Fivetran같은 ETL 도구들은 보통 처리하는 DB 레코드 당 비용을 계산하는데 전체 데이터에서 수정된 데이터를 계산해서 과금한다.
이러한 데이터 파이프라인 도구들은 일반적으로 처음에는 한가지 핵심 기능을 제공하지만 나중에는 이 핵심 기능을 헤치지 않는 선에서 다른 기능들을 추가로 제공한다. Fivetran의 경우에도 500개 이상의 데이터 소스를 연결하여 데이터 웨어하우스나, 데이터 레이크 등으로 데이터를 이동시켜주지만, 점차 ELT에서 T에 해당하는 기능도 함께 제공하게된다. 데이터를 transform 하기 위해 자체 transform 솔루션을 제공하기도 하지만 dbt와 같이 transform에 최적화된 툴을 integration 할 수 있도록 지원하기도한다.
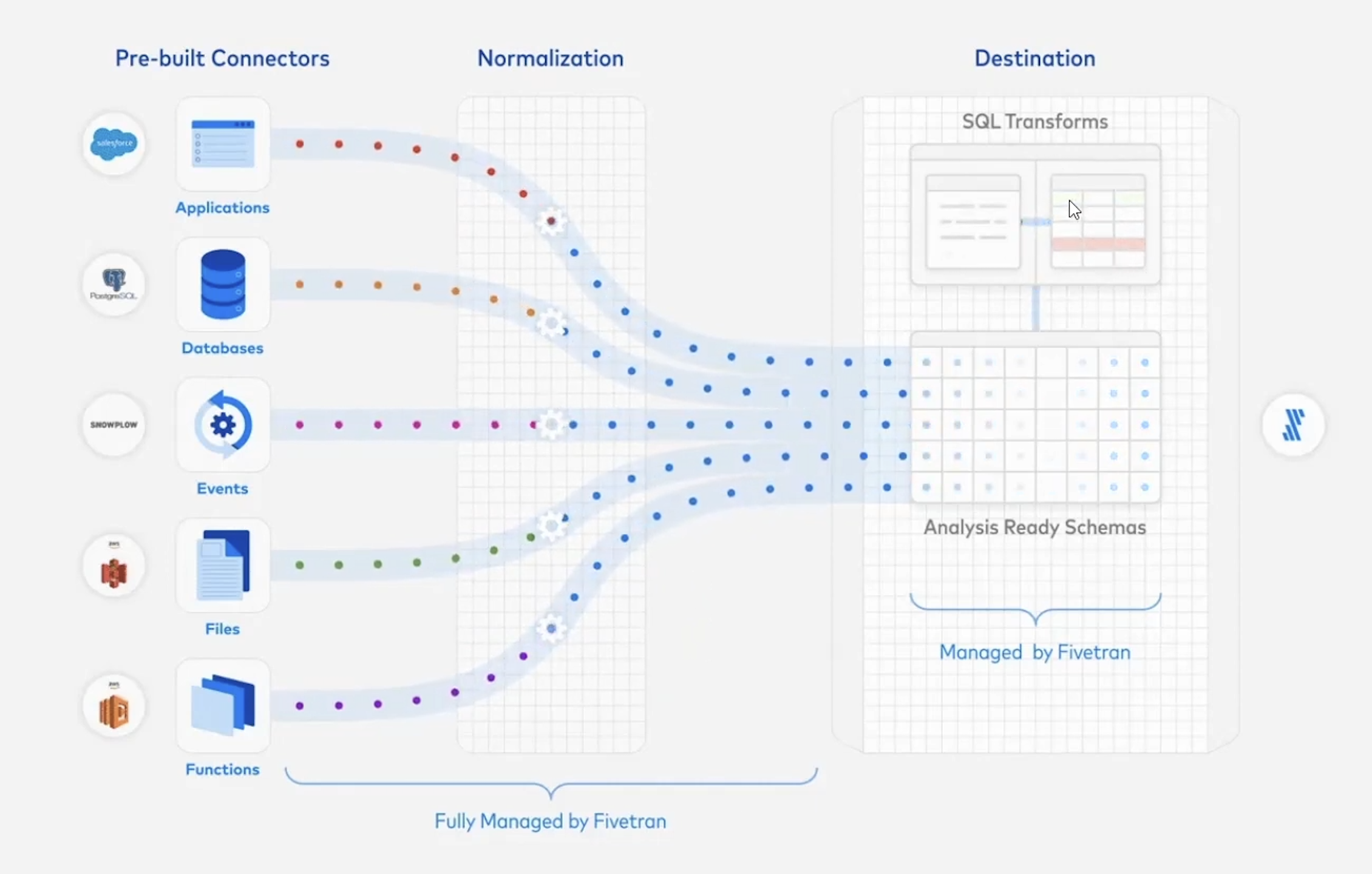 출처:
출처:
Data Modeling
Connector로 데이터를 추출하여 Datalake 또는 Data warehouse에 저장하면 여기에 데이터 모델링 도구를 통합할 수 있다. 대표적으로 dbt 와 lookML 있다. 데이터 웨어하우스나 레이크의 데이터를 쉽게 transform 할 수 있는 도구다.
일반적으로 데이터 분석가와 데이터 엔지니어가 함께 일을 할 때 분석가가 원하는 데이터를 가져올 때 너무 오래 걸리거나 쉽게 가져올 수 없는 경우에는 데이터 엔지니어에게 필요한 데이터를 이야기를 하면 데이터 엔지니어는 데이터 웨어하우스 또는 레이크에서 필요한 데이터를 transform 하여 특정 스키마를 만들게 된다. 데이터 분석가는 데이터 엔지니어가 이러한 스키마들을 여러개 구축해주면 가져다가 사용하는 형태이기 때문에 자신들이 원하는대로 데이터 스키마를 만들기가 어렵다. 데이터 모델링 도구는 이러한 소통 비용을 줄여주는 도구로, dbt의 경우에는 SQL 만으로 데이터 변환 파이프라인을 만들 수 있도록 해준다. dbt를 사용하여 분석 코드를 모듈화하고 데이터 모델에 대해 협업하고, 누가 언제 어떤 sql을 어떻게 바꿨는지에 대한 버전을 관리할 수 있고 프로덕션에 배포하기 전에 not null, uniqueness, parent-child relationships, accepted values, expression tests, custom data tests 등의 쿼리 테스트도 할 수있다. 이렇게 데이터 분석가가 마치 개발자처럼 일할 수 있게 도울 수 있는데 요약하자면 dbt는 transformation용 sql 개발 툴이다. 분석가가 데이터 파이프라인을 관리할 수 있도록 하는 것이 확실히 팀의 생산성을 꽤나 높일 수 있을 것 같다.
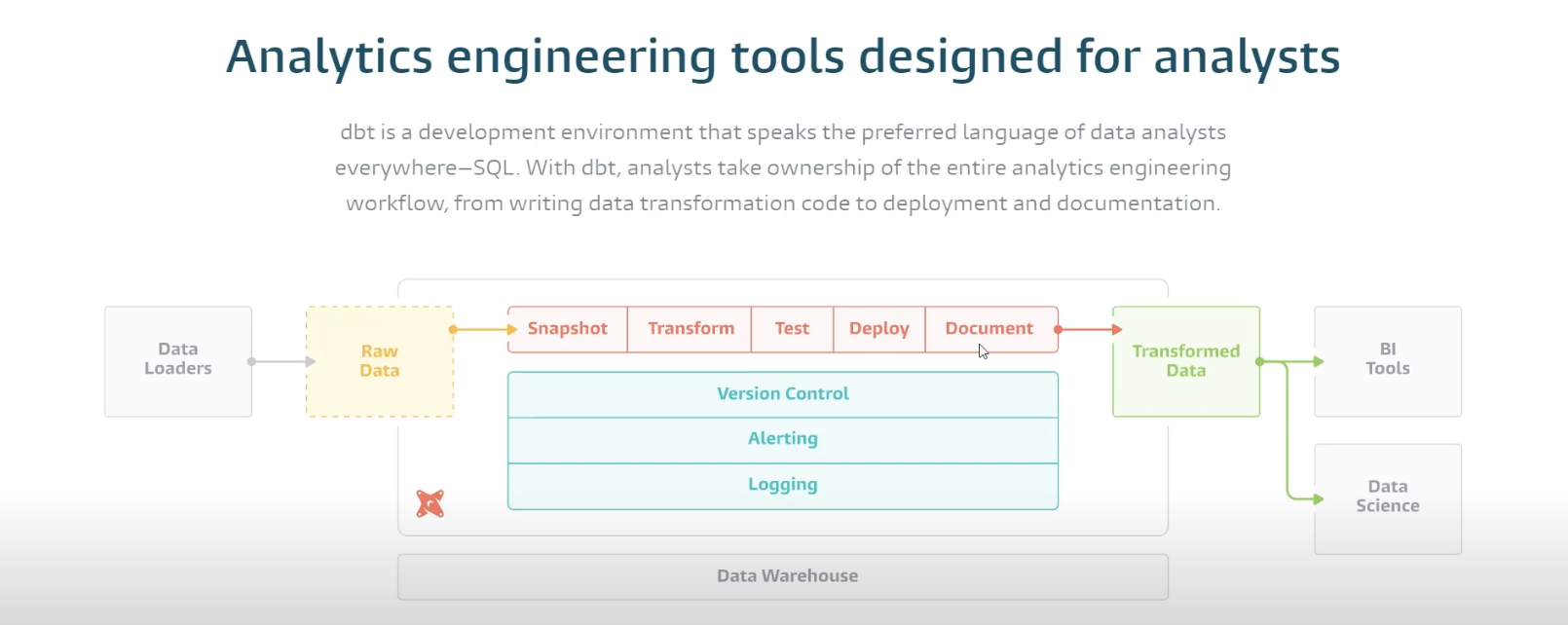 출처:
https://www.getdbt.com/product/what-is-dbt
출처:
https://www.getdbt.com/product/what-is-dbt
Workflow manager
Airflow , Dagster , Perfect 등이 있다. ETL 작업을 workflow 단위로 관리할 수 있는 툴이다. Apache Airflow는 예전에 하둡 에코시스템에 있던 Oozie(하둡 job을 스케줄링 하는 도구)나 Luigi와 비슷하다. Airflow는 요즘 가장 대표적으로 사용하는 workflow management tool로서 크게 task scheduling, distributed execution, dependency management(ex. 이전 task 끝나지 않으면 현재 task를 실행하지 않음)를 지원한다. Airflow는 여러 worker를 분산하여 실행하도록 만들어주는 것이 큰 장점 중 하나이다. Workflow는 DAG 형태로 관리되며 모든 파이프라인이 pure한 파이썬 코드로 작성된다. 2014년에 에어비엔비에서 처음으로 만들고 open source로 공개했다.
예를들어 DAG의 예시를 보자. 온라인 게임 수익 보고 및 예측 그래프에서 각 노드는 수행해야하는 task를 나타낸다. 화살표는 task dependency를 나타내며 점선은 동시에 실행할 수 있는 독립적인 작업을 나타낸다. 우리가 게임의 예상 수익 데이터를 뽑는다고 할 때 광고에서 매출, 앱 스토어 A의 매출, 앱스토어 B의 매출, 앱스토어 C의 매출을 가져와서 더하고, 현재 환률을 적용하고 conversion rate도 가져와서 예상 매출 금액을 계산한다.
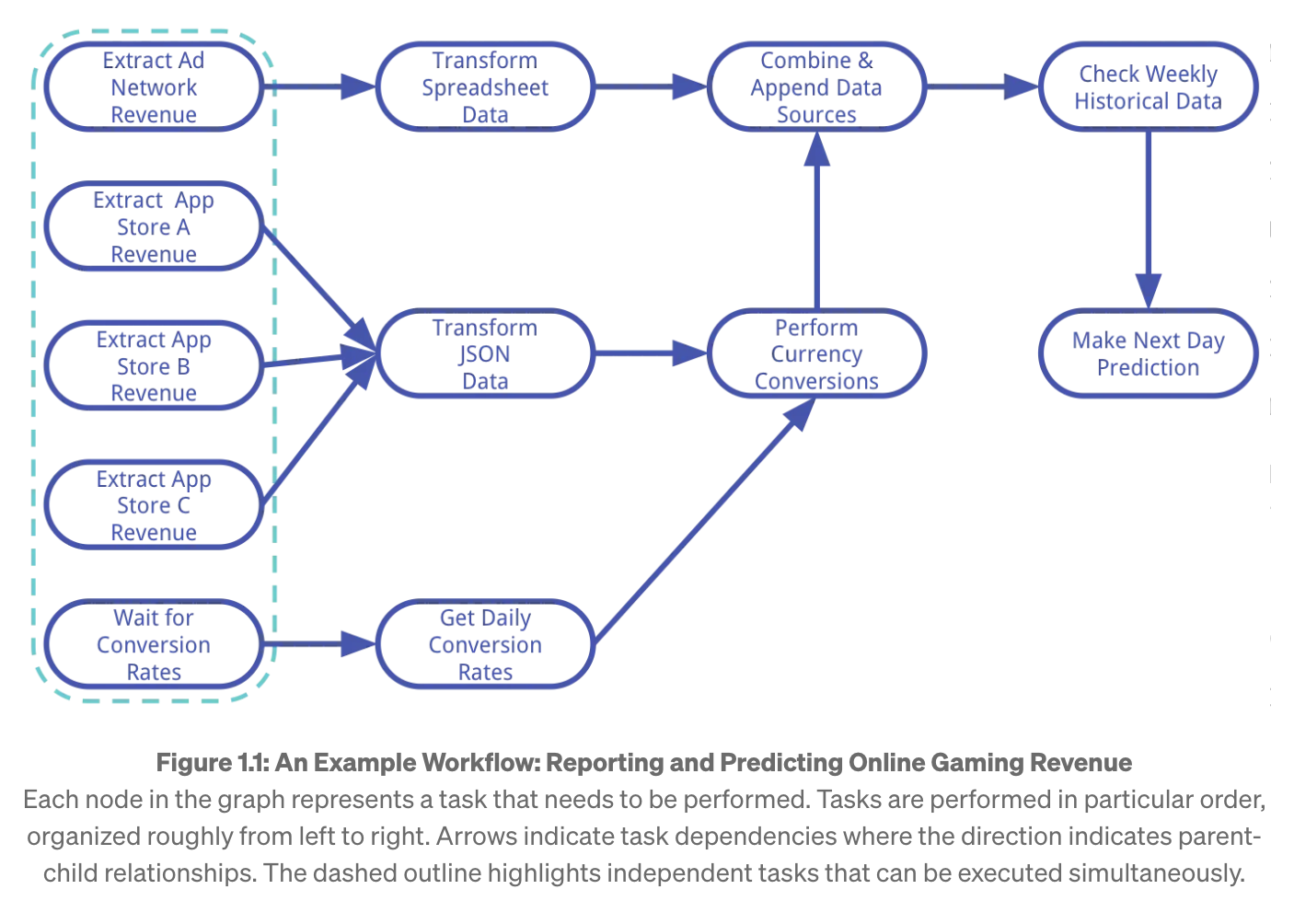 출처:
출처:
Dagster는 airflow와 비슷하다. pandas, spark, sql, dbt 등으로 코드를 만들고 파이프라인을 구축하고 이 파이프라인을 로컬 또는 클라우드에서 실행할 수 있게 한다. Dagster로 만든 데이터 어플리케이션이 어디서든 실행이 가능하다. 데이터 엔지니어들이 ETL 파이프라인을 테스트 해볼 때 클라우드 환경에서 전부 테스트 해볼 수 없기 때문에 로컬에 파이프라인을 만들고 테스트를 한 뒤에 클라우드에 배포하게되는데, dagster는 로컬이나 클라우드든 똑같이 실행되도록 만들어져있다.
Data Processing (Spark, Python libs, Batch Query Engine)
Workflow manager에서 task를 실행할 때, 빅데이터를 다루기 위해 수백, 수천 대의 기기에서 분산 작업을 수행하는 경우가 있는데, 이때 대표적으로 Spark를 사용한다. Spark 외에도 다양한 Python 라이브러리가 데이터 처리를 지원한다. 데이터 처리를 위한 python의 대표적인 라이브러리로 pandas, ray , dask 등이 있다. Dask는 병렬로 여러대의 서버에서 실행하여 큰 작업을 할 수 있게 도와주는 라이브러리로, numpy, pandas, scikit learn의 작업을 여러대의 서버에서 병렬로 실행하도록 도와준다. Ray는 파이썬 코드를 분산 컴퓨팅 할 수 있게 도와주는 도구로 주로 여러대의 서버에서 머신러닝을 돌릴 때 사용한다.
Dask와 Ray는 크게 Collection, Scheduling, Data의 3가지 관점에서 다르다. Dask는 extensive high-level collection APIs(dataframes, distributed arrays 등) 를 지원하여 대규모 데이터 셋을 효율적으로 처리할 수 있게 돕지만 Ray는 그렇지 않다. 그리고 Dask는 centralized scheduler가 있어서 중앙에서 모든 것을 스케줄링하지만 Ray는 분산 bottom-up 스케줄링을 하여 작은 작업 단위로 나누어 병렬로 처리하고 하위 작업이 완료되면 상위 작업을 시작하기 때문에 작업의 대기 시간을 줄여 throughput을 높이고 latency를 줄인다. Data의 측면에서 Ray는 object storage를 사용하여 데이터를 저장하고 관리하며 apache arrow를 통해 데이터를 serailze하고 최소한의 deserialize를 위해 shared memory를 통해 데이터에 접근한다. 하지만 Dask는 object storage를 사용하지 않고 데이터를 여러 파티션으로 나누어 분산처리한다. 주로 네트워크를 통해 데이터를 전달하기 때문에 다양한 serialize를 사용한다. Dask와 Ray 모두 여러대의 서버에서 파이썬 코드를 분산하여 실행하는데, Dask는 여러대의 서버에서 “데이터를 분산"하여 처리하는데 사용하고 Ray는 여러대의 서버에서 머신러닝과 같은 “계산 작업을 분산"하여 처리할 때 주로 사용한다.
Apache Spark는 대규모 분산 데이터 처리를 위해 개발된 cluster-computing framework 이다. 빅데이터를 이야기할 때 여러대의 서버에 나눠서 처리를 해야하는데 그것을 도와주는 프레임 워크이다. 그동안 Hadoop MapReduce와 Spark와 계속 비교가 되어왔다. 일반적으로 Spark가 100배 빠르다고 많이 알려져있는데 Hadoop MapReduce는 Batch processing이 HDFS에 한하여 진행이 되다보니 느렸지만 Spark는 기본적으로 데이터가 메모리에 캐시되다보니 빠르다.
 출처:
https://data-flair.training/blogs/spark-vs-hadoop-mapreduce/
출처:
https://data-flair.training/blogs/spark-vs-hadoop-mapreduce/
스파크의 핵심은 무엇인가? 의 하용호님의 자료를 참고하여 정리해보면, Hadoop MapReduce는 병렬 분산 알고리즘을 활용하여 빅데이터를 처리하기 위한 프로그래밍 모델이다. MapReduce는 여러 작업을 순차적으로 실행하는 프로세스를 띄는데 각 단게에서 MapReduce는 데이터를 읽고, 작업을 수행하고, 다시 HDFS에 저장하는 프로세스를 반복하게 된다. 각 단계마다 거치는 디스크 I/O 지연 시간으로 인해 속도가 느리다. 반대로 Spark에서는 디스크 말고 RAM을 사용하는데 여기서 문제는 램은 중간에 꺼지면 데이터가 날라가기 때문에 처리 중에 에러가 나면 어떻게 해결해야할지가 고민이었다. 즉, fault-tolerant하고 efficient 한 램스토리지를 만들어야했다. 그렇게 RAM을 read-only 로만 써보자는 아이디어가 나왔고 이것이 RDD(Resilient Distributed Datasets) 이다. 한글로 풀어보면 쉽게 복원이 되는 데이터셋이다. RDD는 데이터가 만들어지면 수정이 되지 않는 immuatable한 데이터 셋이다. 어떻게 만들어 졌는지 계보(lineage)를 DAG형태로 기록하여 fault-tolerant를 구현한다. 그리고 lazy-execution 도 함께 진행하는데, 어떻게 만들어졌는지 계보를 그려놓은 상태에서 대강의 execution plan이 다 만들어진 상태에서 실행하므로 자원이 배치된, 배칠될 상황을 미리 고려해서 최적화를 할 수 있다. 결론은 스파크에서는 RAM을 ROM처럼 사용했더니 fault-tolerant & efficient 한 램스토리지를 만들었다는 것이 핵심이다.
MapReduce 처럼 읽기, 쓰기 작업을 반복할 필요없이, 데이터를 메모리로 읽어들이고, 메모리에 캐시해두고 데이터를 재사용하기 때문에 실행 속도가 훨씬 빠르다. 동일한 데이터 세트를 반복적으로 가져와야하는 ML 알고리즘의 속도를 크게 높일 수 있다. 데이터 재사용은 메모리에 캐시되고 여러 spark 작업에서 재사용되는 객체 모음인 RDD에 대한 추상화인 spark Dataframe을 생성하여 수행된다. 아래 그림는 Spark Core를 기반으로 한 전체 프레임워크이다.
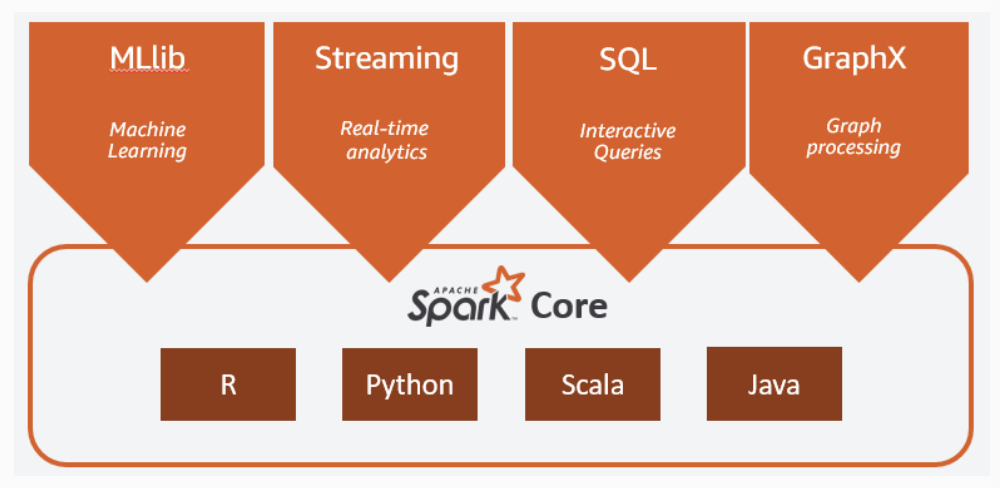 출처:
https://aws.amazon.com/ko/what-is/apache-spark/
출처:
https://aws.amazon.com/ko/what-is/apache-spark/
Spark core는 메모리 관리, 장애 복구, 스케줄링, 스토리지 시스템과 상호작용 등을 담당한다. Java, Scala, Python 등으로 제공되는 API 뒤에 분산 처리의 복잡성을 숨겼다. 그리고 이 위에서 대규모 데이터의 기계학습을 수행하는 라이브러리인 MLlib, 빠른 스케줄링 기능을 활용하여 스트리밍 분석을 수행할 수 있도록 해주는 Spark Streaming, MapReduce보다 최대 100배의 latency가 짧은 대화형 쿼리를 제공하는 분산 쿼리 엔진인 Spark SQL, Spark를 기반으로 구축된 분산 그래프 처리 프레임워크인 GraphX 가 모두 Spark 프레임워크 내에 포함되어있다. 대표적인 Spark 플랫폼으로 Databricks와 EMR이 있다. Databricks는 Spark를 만든 개발자들이 나와서 창업한 회사로 Databricks는 Spark 기반의 data intelligence platform을 만들었다.
Databricks는 데이터 소스를 연결하여 하나의 플랫폼 내에서 처리, 저장, 공유, 분석, 모델 학습 및 서빙을 모두 Spark 위에서 제공한다.
- Data processing scheduling and management, in particular ETL
- Generating dashboards and visualizations
- Managing security, governance, high availability, and disaster recovery
- Data discovery, annotation, and exploration
- Machine learning (ML) modeling, tracking, and model serving
- Generative AI solutions
 (출처:
https://www.databricks.com/spark/comparing-databricks-to-apache-spark
)
(출처:
https://www.databricks.com/spark/comparing-databricks-to-apache-spark
)
Batch Query Engine으로는 Hive를 사용한다. Hive는 HDFS에 있는 데이터를 쿼리하기 위한 엔진으로, 하둡을 통해 데이터를 쿼리하려면 MapReduce job을 짜야하는데 Hive는 SQL을 작성하면 MapReduce job으로 변환되어 처리하도록 도와준다. 또한 Hive는 연결되어있는 DB의 메타데이터 정보를 가지고 있는데 이 메타데이터를 Spark를 사용할 수도 있도록 Hive와 Spark를 함께 사용할 수도 있다. (일단 글로 남겨두지만 같이 사용한다는게 무슨말인지 모르겠다.)
Event Streaming
Spark도 스트리밍을 지원하지만 500ms 단위로 마이크로 배치를 하다보니 마치 실시간으로 처리하는 것처럼 보이지만 사실은 준실시간이라고 할 수 있겠다. 여기서는 정말 실시간으로 데이터가 들어올 때마다 처리를 하는 방법들을 알아볼 것인데 event streaming을 처리하는 툴로 대표적으로 Apache Kafka, Apache Pulsar, AWS Kinesis 등이 있다.
Apache Kafka는 오픈소스 분산 이벤트 스트리밍 플랫폼으로 데이터가 많은 회사들에서는 거의 표준처럼 사용되는 플랫폼이다. Kafka는 write에 최적화된 시스템이다(실제로 만든 사람이 작가인 프란츠 카프카를 좋아해서 이름이 카프카라고 하는데 연관해서 생각하면 편할듯) 링크드인에서 처음 만들었고 오픈소스화해서 현재는 아파치 재단에서 관리중이며 Kafka 를 만든사람이 나와서 창업한 회사가 Confluent이다.
프론트, DB, 채팅 서버 등 각각에서 metric 을 수집한다고 하면 힘들기 때문에 pub/sub 모델이 등장했다. metric 수집이 자체는 좀 더 쉬워지지만 회사 내에서 이벤트로 스트리밍되는 데이터는 아래 그림처럼 metric 뿐만 아니라 logging, tracking 등이 다양하게 발생할 수 있고 그 때마다 각각의 pub/sub을 추가해야하는 문제가 있었다. 그때마다 pub/sub 시스템을 추가할 수 없으니 한번에 처리할 수 있도록 하기 위해 kafka가 탄생했다.
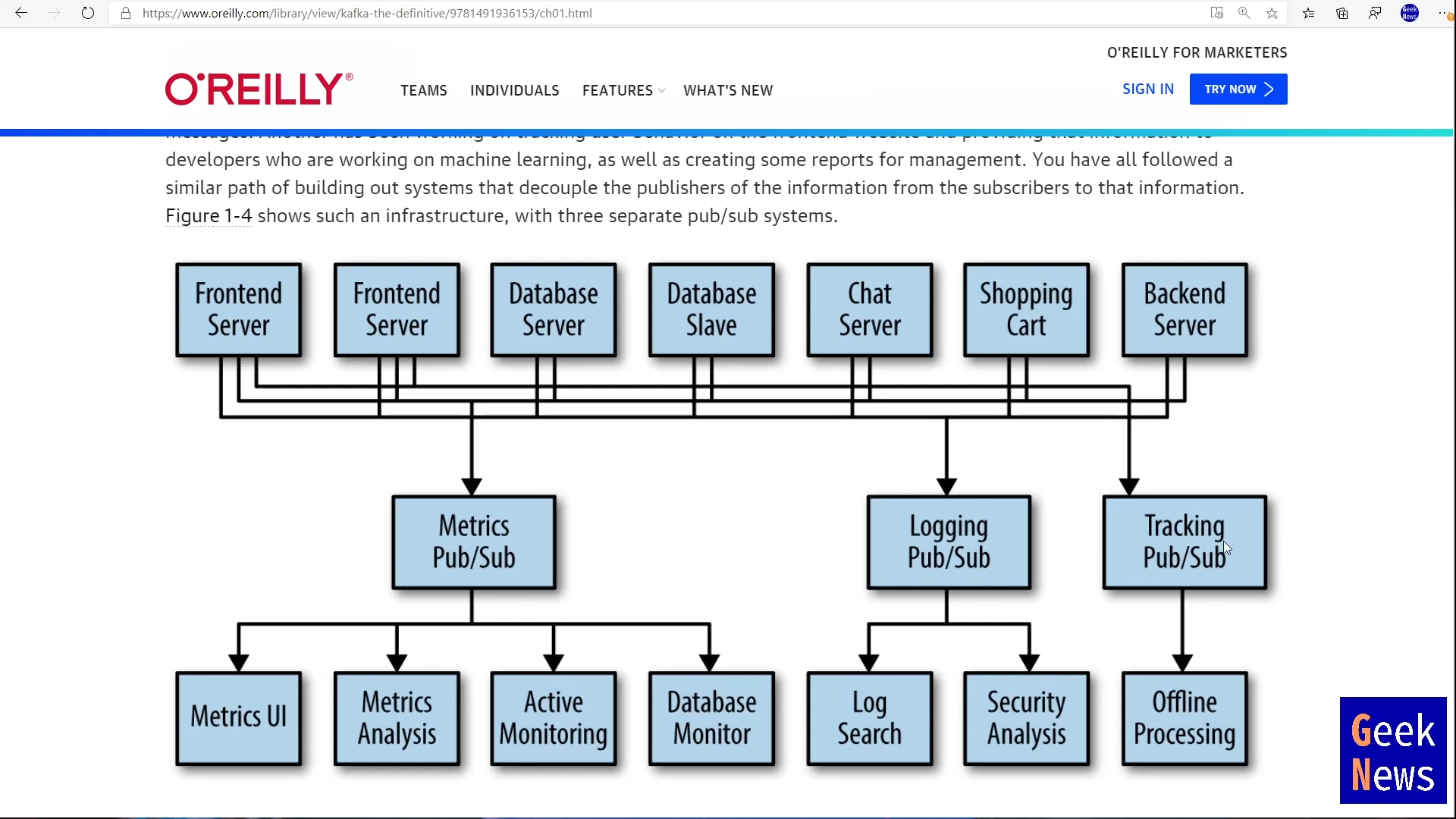 (출처:
https://www.youtube.com/watch?v=c6pJDCdnhbI)
(출처:
https://www.youtube.com/watch?v=c6pJDCdnhbI)
Kafka는 스트리밍 데이터를 수집과 처리에 모두 최적화된 분산형 데이터 저장소이다. 카프카는 앱, 웹, 마이크로서비스, 모니터링 도구, 분석 도구 등에서 나오는 이벤트들을 NoSQL이나 데이터 웨어하우스로 보내는 역할을 주로 하는데 여기서 만들어지는 데이터가 다시 Kafka로 전송된 후에 다른 데이터 스토어에 전달되기도 한다. Kafka의 usecase로 real-time web and log analyticcs, messaging, transaction and event sourcing, decouled microsevices, streaming ETL(ex. CDC를 Kafka를 통해 작업할 수 있다) 등이 있다.
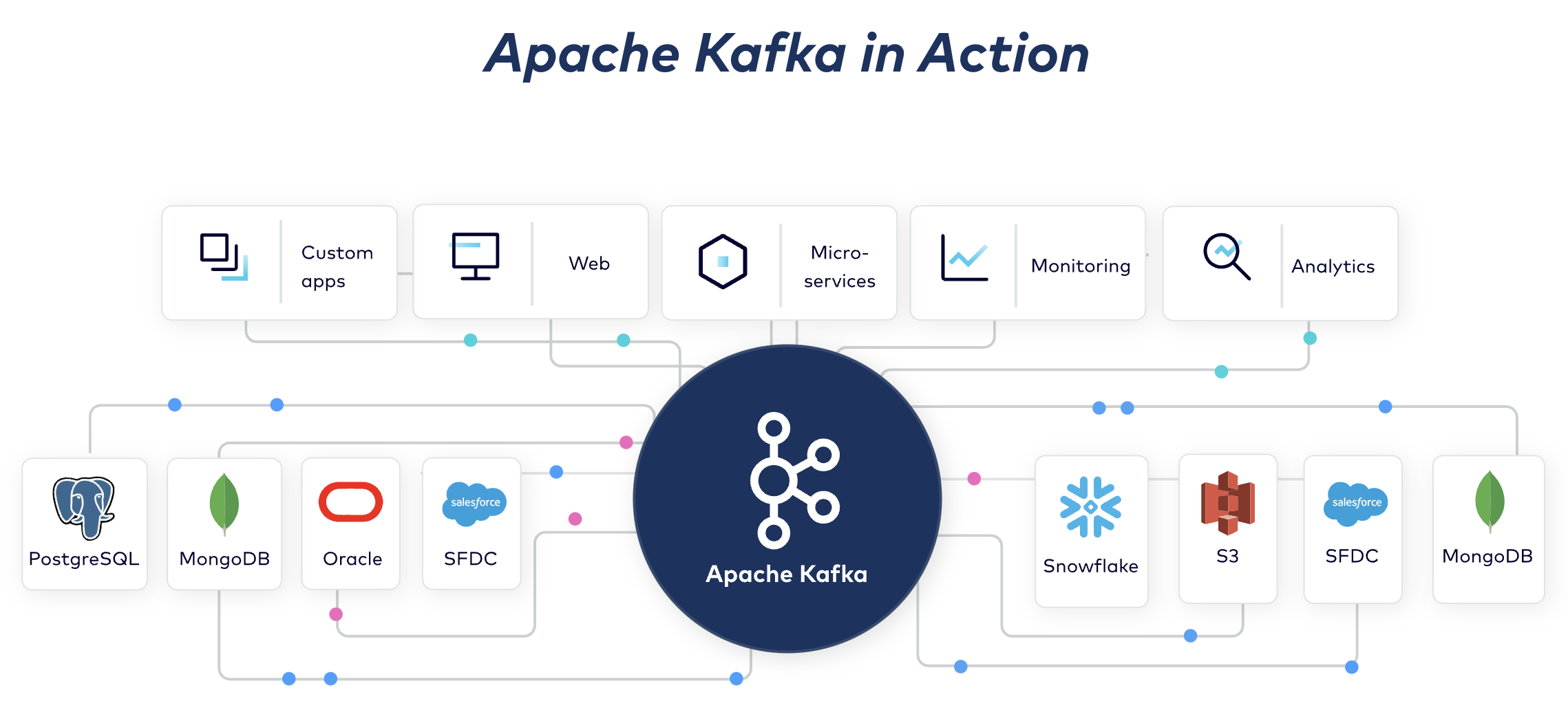 (출처:
https://www.confluent.io/what-is-apache-kafka/#how-kafka-works)
(출처:
https://www.confluent.io/what-is-apache-kafka/#how-kafka-works)
Spark와 Databricks의 관계처럼 Confluent는 Apache Kafka 위에서 카프카 클러스터의 운영에 필요한 Kafka Ops Dashboard, 데이터의 흐름을 모니터링할 수 있는 Data Flow Audit 등의 기능을 제공하는 플랫폼이다.
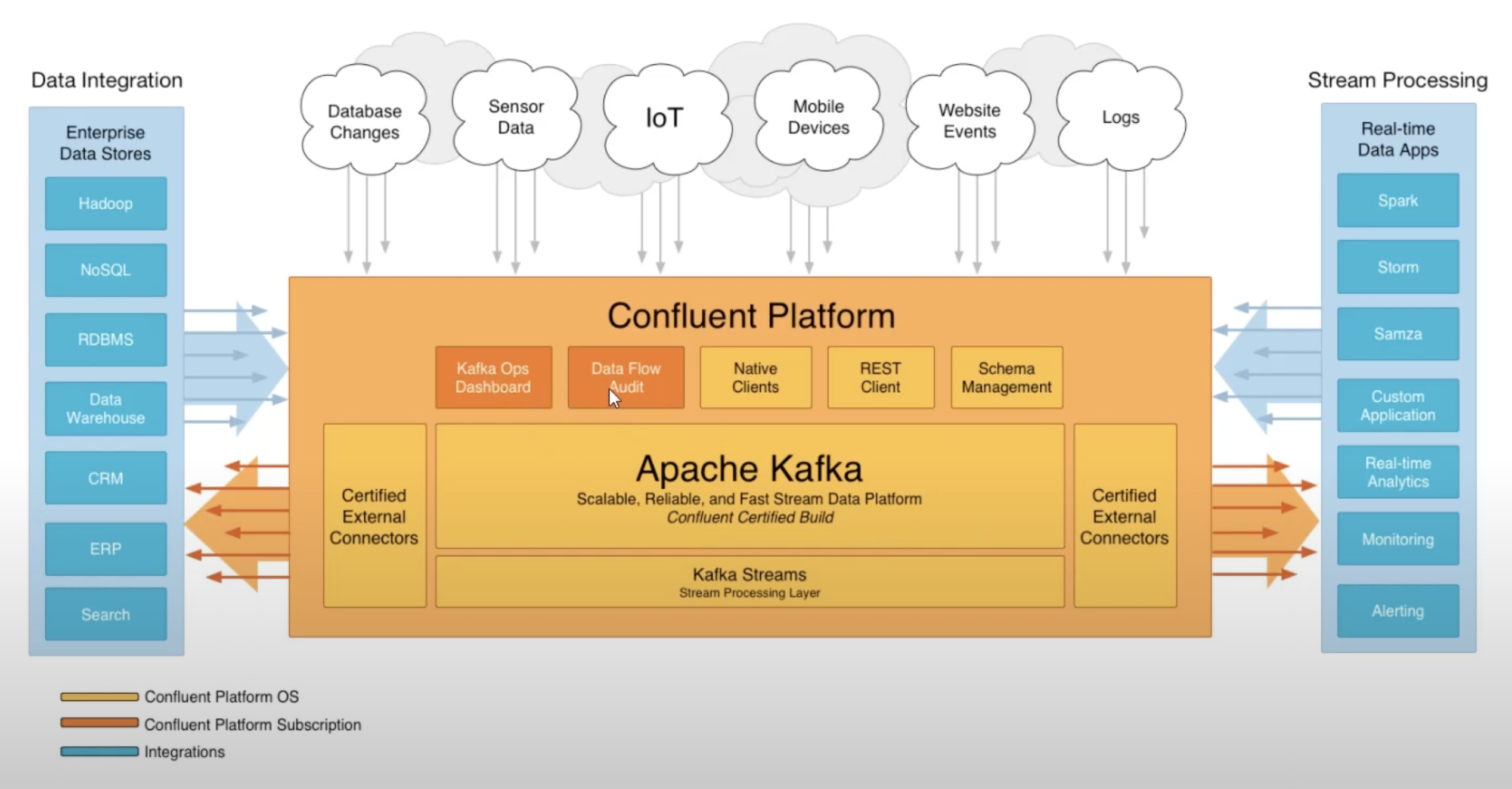 (출처:
https://www.confluent.io/what-is-apache-kafka/#how-kafka-works)
(출처:
https://www.confluent.io/what-is-apache-kafka/#how-kafka-works)
대규모 스트리밍 데이터를 처리해야한다고 하면 대부분 Kafka를 도입하겠지만 중소규모의 스타트업에서는 AWS Kinesis와 Kafka 사이에 고민을 하게 되는데 AWS Kinesis vs Kafka comparison: Which is right for you? 를 참고해서 적절한 기술스택을 선정해보는 것을 추천한다.
Stream Processing
Databricks/Spark의 Spark (Structured) Streaming, Confluent/Kafka의 Kafka Streams, KSQL, ksqlDB 그리고 Apache Flink 등이 있다. Kafka는 기본적으로 producer에서 데이터를 넣어주고 consumer에서 데이터를 가져와 사용하는 형태이지만, 중간에서 Kafka streams와 KSQL을 사용하여 스트림 데이터를 처리할 수 있다. 이후에는
ksqlDB
도 등장했다. 아래는 Kafka Streams와 KSQL을 비교한 그림이다.
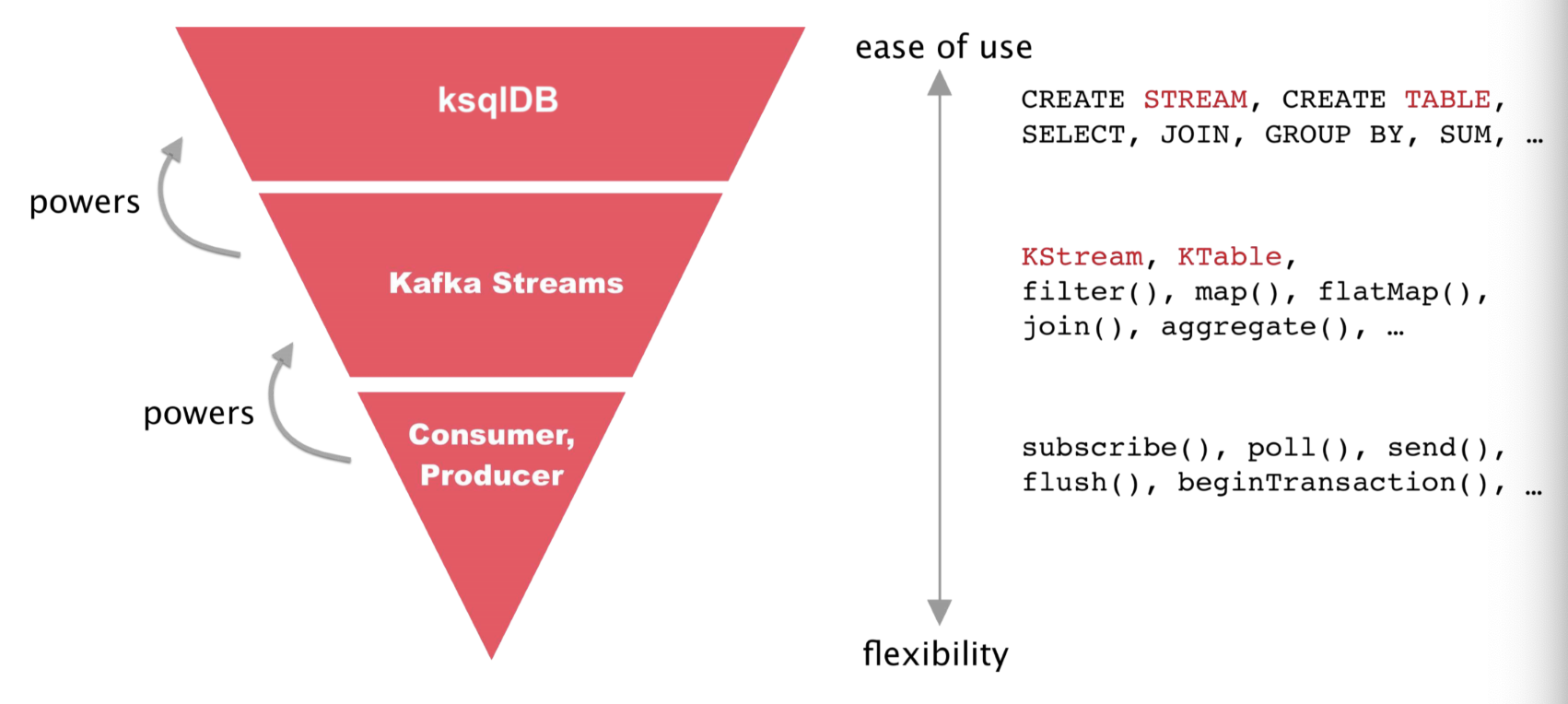 (출처:
https://docs.ksqldb.io/en/0.8.1-ksqldb/concepts/ksqldb-and-kafka-streams/)
(출처:
https://docs.ksqldb.io/en/0.8.1-ksqldb/concepts/ksqldb-and-kafka-streams/)
정리
대략적인 데이터 인프라 아키텍처가 어떤 것들이 있고 서로 어떻게 연결되어있는지를 한눈에 확인하는 용도로 정리해봤다. 그리고 쭉 공부하다보면 데이터 엔지니어링의 핵심은 결국 분산처리인 것 같은데, 스타트업 입장에서는 대부분 분산 처리를 할 정도의 데이터가 없는 것이 현실이고, 거창하게 다양한 데이터 엔지니어링 툴들을 소개했지만 정작 가져다가 사용해볼만한 툴은 몇가지 안될거라고 생각한다.
위 A16Z의 글은 나중에 Emerging Architectures for Modern Data Infrastructure 이 글로 업데이트 되었다.
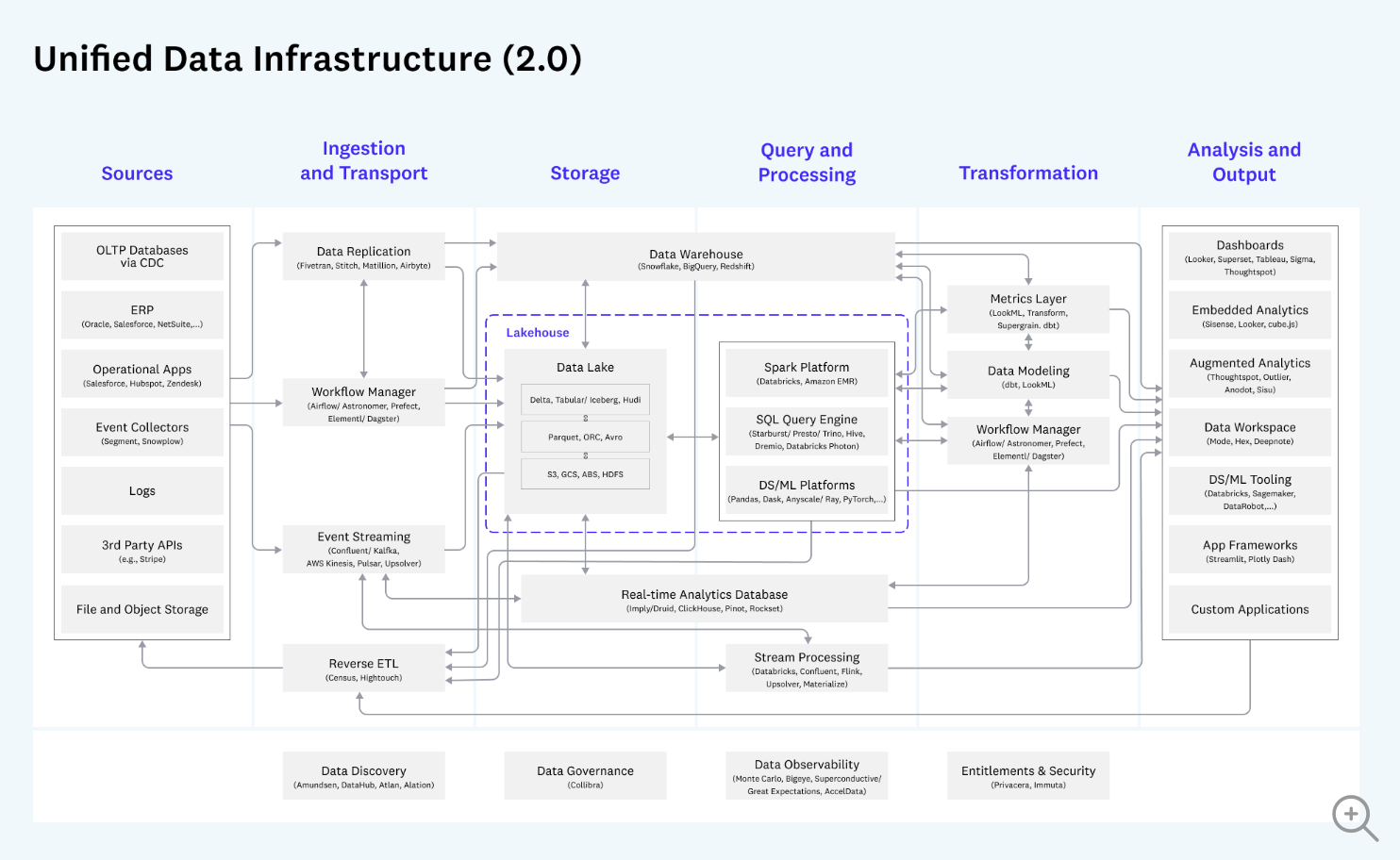
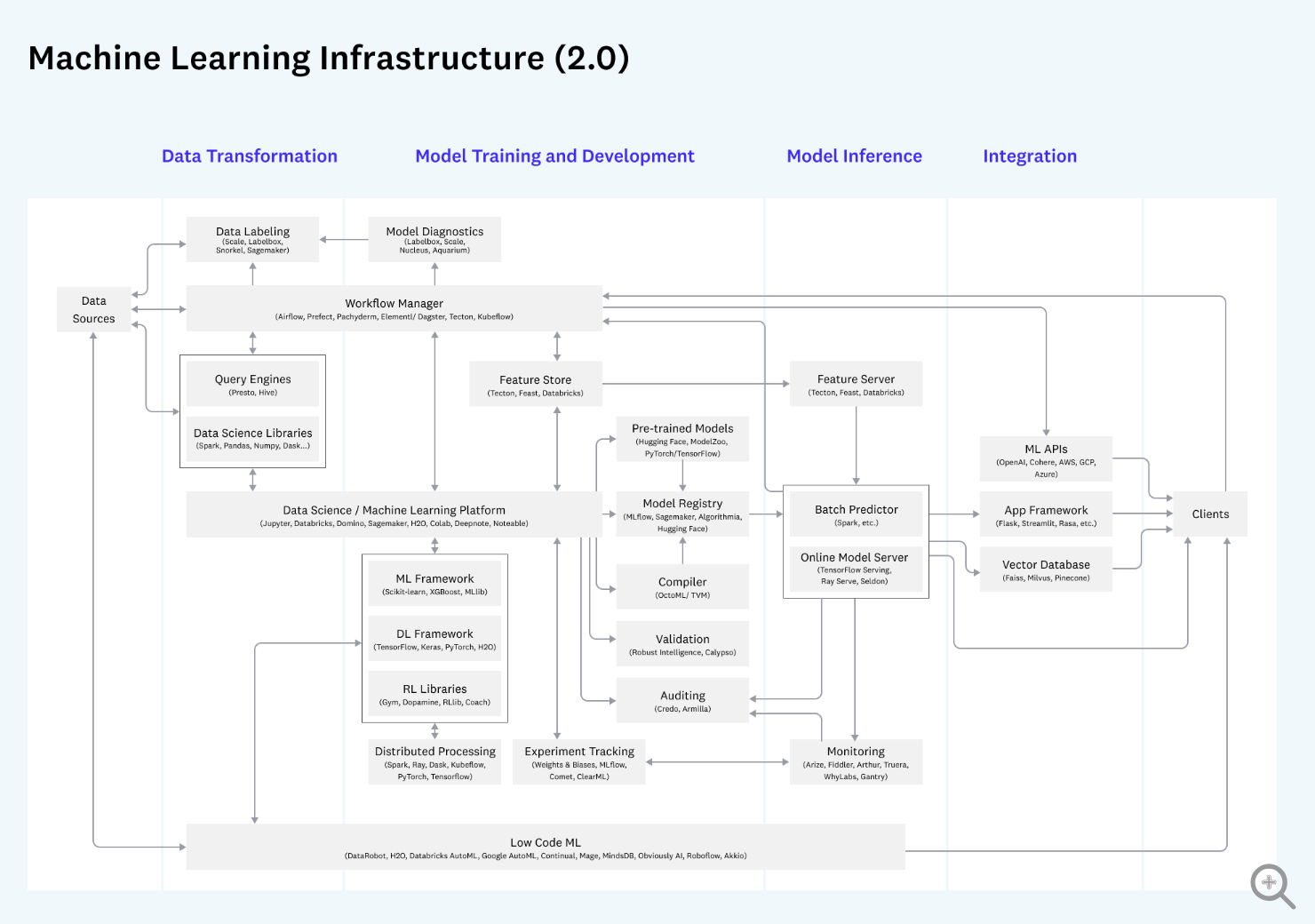 출처:
https://a16z.com/emerging-architectures-for-modern-data-infrastructure/
출처:
https://a16z.com/emerging-architectures-for-modern-data-infrastructure/
The Data Hub and Spoke: Data Infrastructure “3.0” for the Age of Generative AI 이 글도 한번 참고해보자.