백앤드 API의 성능을 개선하고 싶을 때 가장 만만한 곳이 데이터베이스 쿼리이다. Django에서 쿼리 최적화를 할 수 있는 부분을 정리해보자.
Database 최적화
인덱스
인덱스를 추가하는 것은 가장 우선적으로 고려해볼만한 사항이다. Meta.indexes 또는 Field.db_index 를 사용하여 인덱스를 추가하고 filter, exclude, order_by 등을 사용하여 자주 쿼리하는 필드에 인덱스를 추가하면 조회 속도를 높일 수 있다. 일반적으로 인덱스를 속도가 향상되는 것은 맞지만 항상 좋은 것은 아니다. 일단 인덱스를 저장하기 위해 데이터베이스에 추가 저장 공간이 필요하며 많은 인덱스를 생성할 경우에는 부담이 될 수도 있다.그리고 데이터를 삽입, 업데이트, 삭제 할 때는 인덱스도 함께 업데이트 해줘야하므로, 작업의 성능이 저하될 수도 있다. 그래서 처음부터 바로 인덱스를 도입하는 것보다 인덱스 없이 쿼리하다가 특정 쿼리가 자주 사용되거나, 읽기 작업 위주로만 사용되는 테이블이 있다면 그 때 인덱스를 도입하는 것을 권장한다.
적절한 필드 타입 사용하기
그리고 적절한 필드 타입을 사용하는 것도 데이터베이스 최적화에 도움이 된다. 필드에 적절한 자료형을 선택하여 저장공간을 효율적으로 사용할 수 있다. 예를들어 날짜와 시간을 저장하는 필드에 DateTimeField를 사용하면 시간관련 쿼리를 더 효율적으로 작업할 수 있고 텍스트를 저장하는 필드에 CharField나 TextField를 사용하면 문자열을 더 빠르게 검색할 수 있고 숫자를 저장하는 필드에는 IntegerField를 사용하면 sum이나 avg 같은 aggregation 함수를 사용할 수 있고, 이메일 주소를 저장하는 필드에는 EmailField를 사용하면 DB 수준에서 이메일 형식을 검증하여 데이터 무결성을 유지할 수도 있다.
QuerySet 이해하기
상황에 따라 다르겠지만 개인적으로는 될 수 있으면 복잡한 쿼리를 작성하거나, 특정 DB에서만 제공하는 기능을 사용하거나 할 때는 raw SQL을 쓸 수도 있겠지만 대부분의 경우에는 ORM을 사용하는 것을 권장한다. 코드 가독성은 물론이고 SQL 인젝션도 방지할 수 있으며 특정 데이터베이스에 종속적이지 않고 다양한 데이터베이스와 통합될 수 있도록 추상화된 클래스를 제공하고, 스키마 변경이 있을 때는 한곳에서 관리할 수 있도록 해준다. 그래서 기본적으로 장고 Queryset을 이해하는 것이 중요하다.
첫번재로 Queryset은 Lazy 하다는 것을 이해하고 있어야한다 즉 Queryset에 아무리 많은 filter를 달아도 Queryset이 실행(evalutate)되기 전까지는 쿼리가 바로 호출되지 않는다. 아래에 django Docs 의 예시를 들고와보면 실제로 데이터베이스에 3번 호출한 것처럼 보이지만 마지막 print를 실행할 때 데이터베이스에 엑세스하여 실행된다.
>>> q = Entry.objects.filter(headline__startswith="What")
>>> q = q.filter(pub_date__lte=datetime.date.today())
>>> q = q.exclude(body_text__icontains="food")
>>> print(q)
언제 실행되는지는 django Docs 를 참고하면 자세히 알 수 있지만 요약하면, iteration, async iteration, slicing, pickling/caching, repr(), len(), list(), bool() 등을 호출할 때 실행된다.
두번째로 QuerySet이 메모리에 캐시된다는 것도 알고 있어야한다. Queryset이 실행되는 시점에 캐시가 일어나는데 아래 코드를 보면 queryset이 캐시되어 DB 호출이 한번만 일어난다.
>>> queryset = Entry.objects.all()
>>> print([p.headline for p in queryset]) # Evaluate the query set.
>>> print([p.pub_date for p in queryset]) # Reuse the cache from the evaluation.
하지만 다음의 코드의 경우 쿼리셋의 특정 인덱스의 객체만 가져올 때는 cache 되지 않아서 두번의 DB 호출이 일어난다.
>>> queryset = Entry.objects.all()
>>> print(queryset[5]) # Queries the database
>>> print(queryset[5]) # Queries the database again
쿼리 셋의 전체가 실행되어야 cache를 사용할 수 있게 되기 때문에 아래처럼 쿼리셋을 미리 캐시할 수도 있다.
>>> [entry for entry in queryset] # 방법 1
>>> bool(queryset) # 방법 2
>>> entry in queryset # 방법 3
>>> list(queryset) # 방법 4
Django에 구현된 QuerySet 클래스를 보면 len, bool, iter 매직메소드에서 _fetch_all 메소드가 실제로 실행되고 그 결과가 _result_cache 변수에 저장됨을 알 수 있다.
class QuerySet(AltersData):
"""Represent a lazy database lookup for a set of objects."""
def __init__(self, model=None, query=None, using=None, hints=None):
self.model = model
self._db = using
self._hints = hints or {}
self._query = query or sql.Query(self.model)
self._result_cache = None
# ...
def _fetch_all(self):
if self._result_cache is None:
self._result_cache = list(self._iterable_class(self))
if self._prefetch_related_lookups and not self._prefetch_done:
self._prefetch_related_objects()
def __len__(self):
self._fetch_all()
return len(self._result_cache)
def __iter__(self):
self._fetch_all()
return iter(self._result_cache)
def __bool__(self):
self._fetch_all()
return bool(self._result_cache)
실제로 다음 예시 코드를 보면 쿼리가 일어나지 않거나 한번만 일어나도록 코드가 작성되었다. 쿼리셋의 contain, count, exists 메소드를 너무 자주 사용하지 않고 cache를 적절히 사용하여 쿼리를 최적화 할 수 있음을 기억하자.
members = group.members.all()
if display_group_members:
if members:
if current_user in members:
print("You and", len(members) - 1, "other users are members of this group.")
else:
print("There are", len(members), "members in this group.")
for member in members:
print(member.username)
else:
print("There are no members in this group.")
참고로 특정 클래스에서 모델에 쿼리를 호출하는 로직이 담긴 커스텀한 property를 구현할 때, 장고에서 제공하는 @cached_property 데코레이터를 적극적으로 사용하는 것도 좋은 방법이다. 메소드의 결과값을 인스턴스가 유지되는동안 cache 해놓을 수 있다.
세번째로 데이터베이스에 필요한 데이터를 여러번의 쿼리로 가져오는 것보다 한번의 쿼리로 가져오는 것이 속도 측면에서 “일반적으로” 더 낫다. 이를 위해 selected_related()와 prefetch_related() 메소드를 이용하여 데이터베이스 쿼리를 최적화 할 수 있다. selected_related()는 one-to-one 관계의 객체나 정참조 forign key 객체를 불러올 때 사용된다. 즉, 참조된 객체가 하나일 때 사용된다. prefetch_related()는 many-to-many 관계의 객체나 역참조 forign key 객체를 불러올 때 사용한다. 즉, 참조된 객체가 여러개 일 때 사용된다.
아래의 예시를 한번 보자. Publisher 모델에서 Author와 Book 모델을, Book 모델에서 Author 모델을 정참조 하고 있다. 반대로 Author 모델에서 Book 모델을, Book 모델에서 Publisher 모델을 역참조하고 있다.
class Publisher(models.Model):
book = models.ForeignKey("Book", on_delete=models.CASCADE)
date = models.DateField()
class Author(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=200)
author = models.ForeignKey(Author, on_delete=models.CASCADE)
아래 쿼리를 보면 Book에서 selected_related 쿼리로 Author 모델을 함께 쿼리하면 inner join 문으로 한번에 쿼리됨을 알 수 있다.
>>> Book.objects.select_related("author").all()
SELECT "testapps_book"."id",
"testapps_book"."title",
"testapps_book"."author_id",
"testapps_author"."id",
"testapps_author"."name"
FROM "testapps_book"
INNER JOIN "testapps_author"
ON ("testapps_book"."author_id" = "testapps_author"."id")
>>> Publisher.objects.select_related("book", "book__author").all()
SELECT "testapps_publisher"."id",
"testapps_publisher"."author_id",
"testapps_publisher"."book_id",
"testapps_publisher"."date",
"testapps_book"."id",
"testapps_book"."title",
"testapps_book"."author_id",
"testapps_author"."id",
"testapps_author"."name"
FROM "testapps_publisher"
INNER JOIN "testapps_book"
ON ("testapps_publisher"."book_id" = "testapps_book"."id")
INNER JOIN "testapps_author"
ON ("testapps_book"."author_id" = "testapps_author"."id")
반대로 prefetch_related를 실행해보자. Author에서 prefetch_related로 Book도 함께 불러오면 총 두번의 쿼리를 실행하게 된다. 먼저 Author 객체를 전부 불러온 뒤에, author_id (1, 2, 3, 4, 5) 에 해당하는 Book을 불러온다.
>>> Author.objects.prefetch_related("book_set").all()
SELECT "testapps_author"."id",
"testapps_author"."name"
FROM "testapps_author"
SELECT "testapps_book"."id",
"testapps_book"."title",
"testapps_book"."author_id"
FROM "testapps_book"
WHERE "testapps_book"."author_id" IN (1, 2, 3, 4, 5)
그럼 여러 테이블을 prefetch_related로 가져와보자. 위와 비슷하게 먼저 Author를 모두 불러오고, author_id (1, 2, 3, 4, 5)에 해당하는 Book을 불러오고, book_id (1, 2, 3, 4)에 해당하는 Publisher를 불러온다.
>>> Author.objects.prefetch_related("book_set", "book_set__publisher_set").all()
SELECT "testapps_author"."id",
"testapps_author"."name"
FROM "testapps_author"
SELECT "testapps_book"."id",
"testapps_book"."title",
"testapps_book"."author_id"
FROM "testapps_book"
WHERE "testapps_book"."author_id" IN (1, 2, 3, 4, 5)
SELECT "testapps_publisher"."id",
"testapps_publisher"."author_id",
"testapps_publisher"."book_id",
"testapps_publisher"."date"
FROM "testapps_publisher"
WHERE "testapps_publisher"."book_id" IN (1, 2, 3, 4)
prefetch_related 와 selected_related를 함께 사용해보자. Book과 Author를 join 하여 가져오고, book_id (1, 2, 3, 4)에 해당하는 Publisher를 가져온다.
>>> Book.objects.select_related("author").prefetch_related("publisher_set").all()
SELECT "testapps_book"."id",
"testapps_book"."title",
"testapps_book"."author_id",
"testapps_author"."id",
"testapps_author"."name"
FROM "testapps_book"
INNER JOIN "testapps_author"
ON ("testapps_book"."author_id" = "testapps_author"."id")
SELECT "testapps_publisher"."id",
"testapps_publisher"."author_id",
"testapps_publisher"."book_id",
"testapps_publisher"."date"
FROM "testapps_publisher"
WHERE "testapps_publisher"."book_id" IN (1, 2, 3, 4)
prefetch_related의 효과를 제대로 경험하기 위해 N+1 쿼리 문제 상황을 만들어보자. N+1 쿼리 문제는 ORM을 사용할 때 자주 발생하는 성능 문제 중 하나로, 처음 쿼리로 N개의 레코드를 가져오고 각 레코드에 대해 추가로 1개의 쿼리를 실행하는 상황을 말한다. Django에서는 N+1 쿼리 문제를 해결하기 위해 selected_related 와 prefetch_related를 적절히 사용한다. 아래 쿼리 예시에서는 select_related 만을 사용하여 Book과 Author를 함께 불러온 후에, 각 book 객체를 돌면서 publisher을 역참조하여 가져왔는데, publisher를 가져올 때마다 쿼리가 호출됨을 알 수 있다. 그래서 book 객체의 개수만큼 총 4번의 쿼리가 호출되었다. 이는 N+1 쿼리 문제에 해당된다.
>>> books = Book.objects.select_related("author").all()
SELECT "testapps_book"."id",
"testapps_book"."title",
"testapps_book"."author_id",
"testapps_author"."id",
"testapps_author"."name"
FROM "testapps_book"
INNER JOIN "testapps_author"
ON ("testapps_book"."author_id" = "testapps_author"."id")
>>> [book.publisher_set.all() for book in books] # 4번의 쿼리 호출
여기서는 select_related, prefetch_related를 모두 사용하여 Book, Author, Publisher를 한번에 가져오고, book 객체를 돌면서 publisher를 가져온다. 처음에 쿼리 두번만 호출하고 book 객체를 돌면서 publisher를 가져올 때는 따로 쿼리를 호출하지 않는다.
>>> books = Book.objects.select_related("author").prefetch_related("publisher_set").all()
SELECT "testapps_book"."id",
"testapps_book"."title",
"testapps_book"."author_id",
"testapps_author"."id",
"testapps_author"."name"
FROM "testapps_book"
INNER JOIN "testapps_author"
ON ("testapps_book"."author_id" = "testapps_author"."id")
SELECT "testapps_publisher"."id",
"testapps_publisher"."author_id",
"testapps_publisher"."book_id",
"testapps_publisher"."date"
FROM "testapps_publisher"
WHERE "testapps_publisher"."book_id" IN (1, 2, 3, 4)
>>> [book.publisher_set.all() for book in books] # 0번의 쿼리 호출
앞에서 여러번의 쿼리보다 한번의 쿼리로 데이터를 로드하는 것이 속도 측면에서 “일반적으로” 더 효율적이라고 했다. 그럼 이제 일반적이지 않은 경우를 보자. 대부분 한번의 쿼리는 시간이 얼마 걸리지 않지만 가져오는 데이터 셋의 크기가 클 경우에는 한번의 쿼리라도 시간이 오래걸릴 수 있다. 이 때는 exists와 iterator 함수를 적절히 사용해주면 불필요한 데이터 셋을 로드하는 것을 방지하여 메모리 사용량을 최적화할 수 있다. 실제로 쿼리셋의 레코드의 존재여부를 판단할 때 if 문에 쿼리셋을 넣게 되면 모든 레코드를 불러오게 된다. 이런 경우 .exists() 메소드로 레코드를 전부 불러오지 않고 존재성만 판단할 수 있다. 그리고 쿼리셋을 반복해서 레코드를 가져올 때는 iterator 함수를 사용하자.
for instance in BigSizeModel.objects.all().iterator():
do_something(instance)
실제로 iterator 메소드는 기본적으로 2000개의 청크 단위로 나누어 객체를 가져오게 되어 메모리 사용에 이점을 볼 수 있다.
def _iterator(self, use_chunked_fetch, chunk_size):
iterable = self._iterable_class(
self,
chunked_fetch=use_chunked_fetch,
chunk_size=chunk_size or 2000,
)
if not self._prefetch_related_lookups or chunk_size is None:
yield from iterable
return
iterator = iter(iterable)
while results := list(islice(iterator, chunk_size)):
prefetch_related_objects(results, *self._prefetch_related_lookups)
yield from results
또 다른 방법으로 필요없는 필드는 가져오지 않는 방법이 있다. QuerySet.defer() 또는 QuerySet.only()를 사용하여 필요한 필드만 가져올 수도 있다. defer와 only 두 메소드 모두 특정 필드를 lazy loading 하여 가져오는데, 매우 큰 텍스트 필드나 데이터베이스에서 처리하기 어려운 필드를 포함하지 않을 수 있지만 만약 추후에 해당 필드에 접근하게 될 경우 별도로 데이터베이스 쿼리를 한번 더 실행하여 가져오게 된다. 아래 예시에서 only와 defer를 실행한 SQL 결과를 출력했다. 실제로 only는 특정 필드만 포함하고 defer는 특정 필드를 제외하여 DB를 호출한다. 하지만 아래의 only로 가져온 QuerySet에 pub_date를 가져오거나, defer로 가져온 QuerySet의 question_text를 가져올 때는 전체 쿼리를 한번 더 호출하게 된다. 실제로 only와 defer는 QuerySet 최적화에 도움을 줄 수 있긴하지만 어떤 필드를 지연시켰는지 일일이 확인하기도 힘들고, 불필요한 쿼리를 두번씩 호출하는 경우가 발생할 수 있으니 너무 자주 사용하지 않는 것을 권장한다.
class Question(models.Model):
question_text = models.CharField(max_length=200)
pub_date = models.DateTimeField("date published")
class Choice(models.Model):
question = models.ForeignKey(Question, on_delete=models.CASCADE)
choice_text = models.CharField(max_length=200)
votes = models.IntegerField(default=0)
>>> Question.objects.only("question_text").all()
SELECT "testapps_question"."id",
"testapps_question"."question_text"
FROM "testapps_question"
>>> Question.objects.defer("question_text").all()
SELECT "testapps_question"."id",
"testapps_question"."pub_date"
FROM "testapps_question"
혹시나 필요없는 필드를 호출할까봐 걱정된다면 .values() 또는 .values_list() 메소드로 특정 필드를 지정하여 dict 또는 list의 형태로 들고 올 수도 있다.
실제로 사이즈가 큰 텍스트 데이터가 포함된 테이블을 쿼리할 때, exists 메소드를 사용하여 쿼리셋을 호출하지 않고 레코드의 존재성만 검증하여 분기처리를 하고, values로 필요한 특정 필드만 가져오기만 했는데도 API 속도를 45초에서 1.7초 줄일 수 있었다. 그래서 한번에 많이 들고온다고 무조건 좋은 것도 아니고, 여러번에 걸쳐서 들고온다고 무조건 좋은 것도 아니다. 그 상황에 맞게 적절하게 최적화가 필요하다.
# 개선 전
queryset = BigSizeModel.objects.all()
if not queryset:
return
for obj in queryset:
do_something(obj)
# 개선 후
queryset = BigSizeModel.objects.values("field1", "field2")
if not queryset.exists():
return
for obj in queryset:
do_something(obj)
네번째로 bulk 메소드를 사용해서 성능이 올라가는 경우가 있다. 여러번 추가, 수정, 삭제 쿼리를 날리는 것보다, 한번에 하는게 속도 측면에서 일반적으로 이득이다. 한번에 많은 데이터를 메모리에 로드하므로 메모리 사용량이 순간적으로 증가하여 뻗을 수 있으니 적절한 배치크기를 설정하는 것이 중요하다.
# Craete
Entry.objects.bulk_create(
[
Entry(headline="This is a test"),
Entry(headline="This is only a test"),
]
)
# Update
entries[0].headline = "This is not a test"
entries[1].headline = "This is no longer a test"
Entry.objects.bulk_update(entries, ["headline"])
아래보다 위의 코드가 더 선호된다.
# Create
Entry.objects.create(headline="This is a test")
Entry.objects.create(headline="This is only a test")
# Update
entries[0].headline = "This is not a test"
entries[1].headline = "This is no longer a test"
Entry.objects.bulk_update(entries, ["headline"])
SQL
쿼리를 최적화하려면 결국 raw SQL에 대해 잘 알고 있어야한다. 아래 내용은 책 SQL 레벨업 의 내용의 일부를 가져와 정리했다.
DBMS 아키텍처 개요
Oracle, Microsoft SQL Server, DB2, PostgreSQL, MYSQL 등의 RDB 제품은 굉장히 다양하다. 이 제품들은 각각의 특징이 있고 내부 아키텍처들도 조금씩 다르지만 관계 모델이라는 수학적인 이론을 바탕으로 하여 결국 기본적인 구조 자체는 모두 비슷하다.
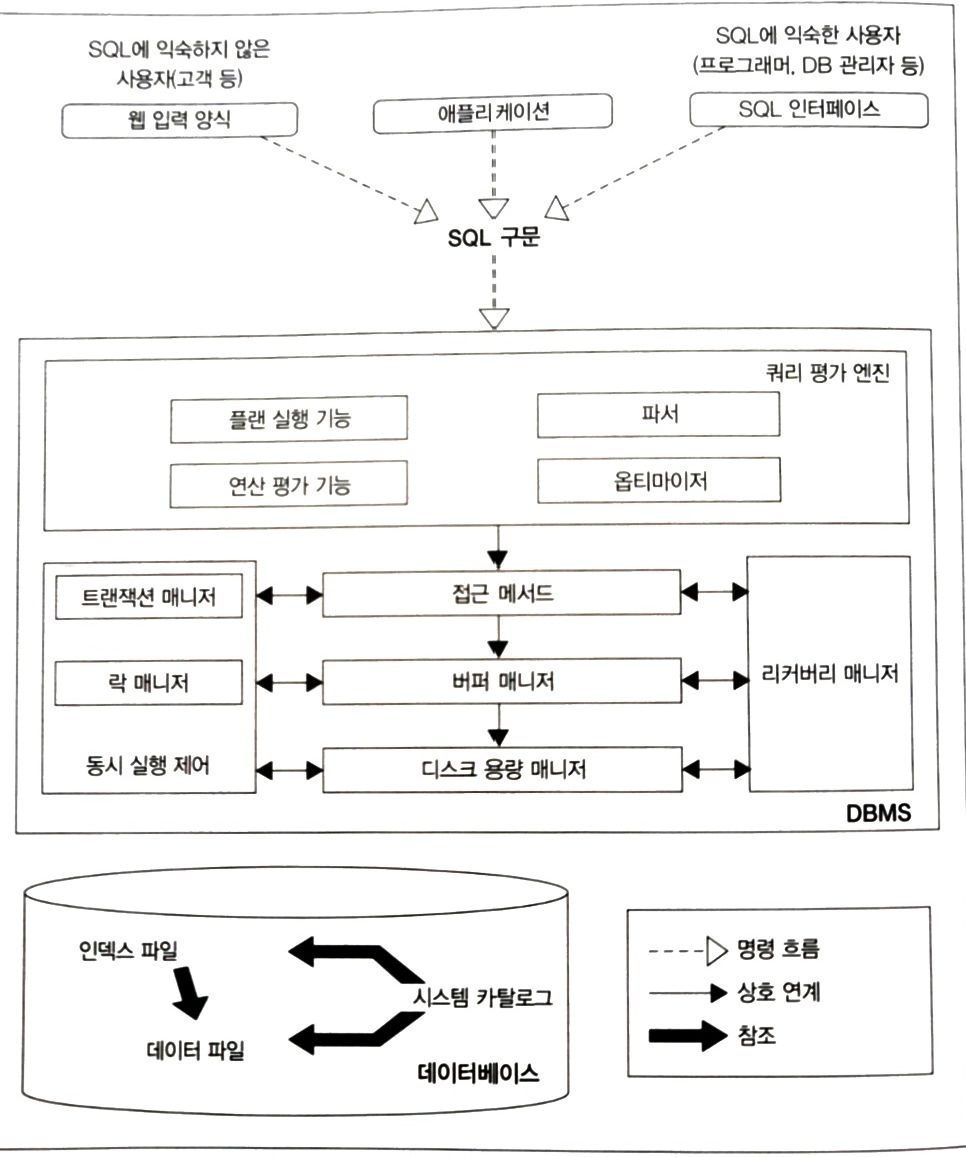 출처: SQL 레벨업 > 그림 1-1 DBMS 아키텍처
출처: SQL 레벨업 > 그림 1-1 DBMS 아키텍처
쿼리 평가 엔진 : SQL 구문을 분석하고 어떤 순서로 기억장치의 데이터에 접근할지 결정한다. 이때 결정되는 계획을 실행 계획(또는 실행 플랜)(explain plan)이라고 부른다. 이 실행 계획의 데이터 접근 방법을 접근 메소드(access method) 라고 부른다.
버퍼 매니저: DBMS는 버퍼라는 특별한 메모리 영역을 사용하는데 이 메모리 영역을 관리하는 매니저다.
디스크 용량 매니저: 어디에 어떻게 데이터를 저장할지를 관리한다. 데이터의 읽고, 쓰기를 제어한다.
트랜잭션 메니저와 락 매니저: 수백에서 수천명의 사람이 동시에 DB에 접근해서 사용한다. 이때 각 처리는 DBMS 내부에서 트랜잭션이란 단위로 관리되는데, 이러한 트랜잭션의 정합을 유지하면서 실행시키고, 필요한 경우 데이터에 락을 걸어 다른 사람의 요청을 대기시킨다.
리커버리 매니저: 장애에 대비해 데이터를 정기적으로 백업하고 문제가 일어났을 때 복구하는 기능을 수행한다.
DBMS와 버퍼
버퍼는 SQL 구문의 속도를 빠르게 하기 위해 사용되며, 데이터를 어떻게 어느정도의 기간동안 메모리에 저장할지는 버퍼 매니저가 결정한다. DBMS가 사용하는 3개의 메모리 영역이 존재한다.
첫번째는 데이터 캐시 메모리 영역이다. 디스크에 있는 데이터의 일부를 캐시 메모리 영역에 유지하며 select를 빠르게 하기 위해서 사용한다.
두번째로 로그 버퍼 메모리 영역으로 갱신 처리(insert, update, delete)와 관련이 있다. SQL문을 작성하여 실행하면, 로그 버퍼 메모리 영역으로 이동하고, 메모리에서 디스크로 업데이트(commit)를 하면 디스크에 변경이 일어난다. 즉 SQL 문 작성 -> 로그 버퍼 메모리 영역 -> 디스크 영역 변경 순서로 일어난다. 로그 버퍼가 크게 할당 되었다면 갱신 처리에 큰 부하가 걸릴 것을 고려한 설계이며 반대로 데이터 캐시가 많이 할당되었다면 검색 처리가 중심이 된 설계이다.
세번째는 워킹 메모리 영역이다. 이 영역은 정렬 또는 해시 관련 처리에 사용되는 작업용 영역이다. 정렬은 order by, set operation(ex. union, intersect), window function(ex. rank over) 등의 기능을 사용할 때 실행된다. 해시는 join과 group by에서 해시 테이블을 만들어 시스템 성능을 향상 시킨다. 워킹 메모리 영역은 DBMS 종류마다 다른데 예를들어 PostgreSQL 의 경우 워크 버퍼 메모리 영역(매개변수: work_mem)이라고 부르며 MySQL의 경우 정렬 버퍼 메모리 영역(매개변수: sort_buffer_size) 라고 부른다.
이런 메커니즘을 보면 DBMS 는 “메모리가 부족하더라도 무언가를 처리하려고 계속 노력하는 미들웨어” 라고 볼수도 있겠다. 예를들어 자바는 heap 크기가 부족하면 oom 오류를 발생시켜 모든 처리를 중단시킬 수도 있는데 말이다. 하지만 DB는 메모리가 부족하면 메모리 스왑이 발생하거나 쿼리 성능이 저하될 수는 있겠지만 SQL 구문에 오류를 내뱉진 않는다.
DBMS 와 실행계획
쿼리 평가 엔진에서 쿼리가 처리되는 흐름은 다음과 같다.
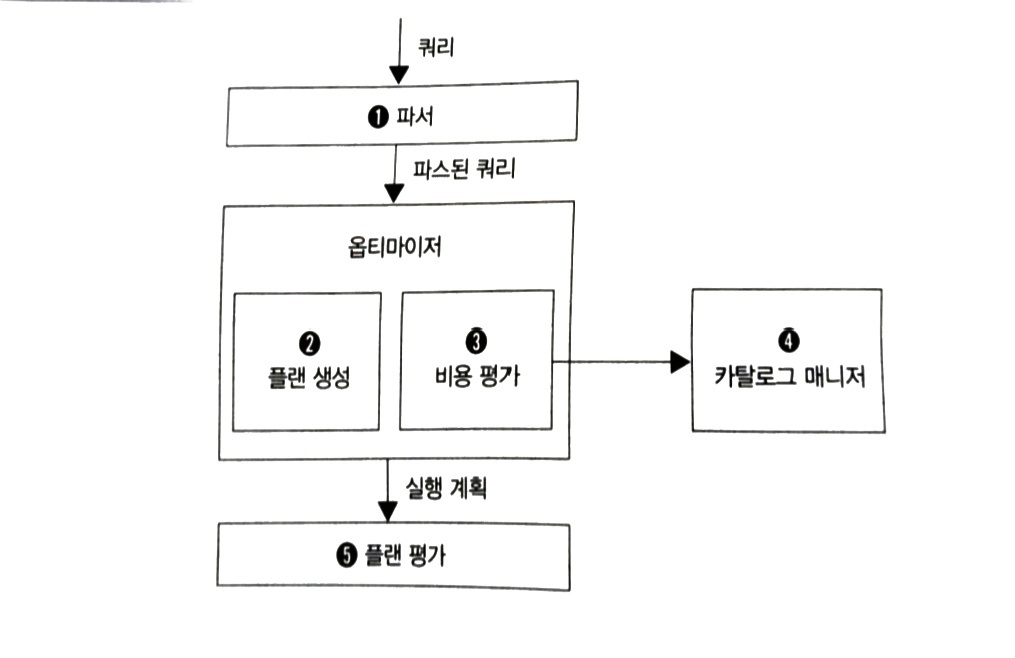 출처: SQL 레벨업 > 그림 1-7 DBMS의 쿼리 처리 흐름
출처: SQL 레벨업 > 그림 1-7 DBMS의 쿼리 처리 흐름
파서(Parser): 구문 분석을 진행하는데 예를들어 쉼표 쓰는걸 잊거나, from에 없는 테이블을 쓰거나 한 것들을 잡아낸다.
옵티마이저(optimizer): 인덱스 유무, 데이터의 분산 또는 편향 정도, DBMS 내부 매개변수 등을 고려하여 실행계획을 짜고 이들의 비용을 계산하여 가장 낮은 비용의 실행계획을 선택한다.
카탈로그 매니저: 옵티마이저가 실행계획을 짤 때 옵티마이저에게 카탈로그를 제공한다. 카탈로그는 테이블과 인덱스의 통계정보이며 예를들어 각 테이블의 레코드 수, 각 테이블 필드 수와 필드 크기, 필드의 cardinality(값 개수), 필드 값의 히스토그램(어떤 값이 얼마나 분포해있는지), 필드 내부 NULL 수, 인덱스 정보 등을 알 수 있다. 특히 올바른 카탈로그 정보가 SQL의 성능에 있어서 굉장히 중요하다. 테이블의 데이터가 바뀌면 카탈로그의 통계 정보도 함께 갱신되어야 한다. 예를들어 PostgreSQL에서는 ANALYZE [스키마이름].[테이블이름] 으로 통계 정보를 갱신한다.
실행 계획이 SQL 구문의 성능을 결정
SQL을 실행할 때 지연이 발생하면 제일 먼저 실행계획을 살펴봐야한다. 모든 DBMS 는 실행계획을 조사할 수 있는 명령어를 제공한다. PostgreSQL에서는 EXPLAIN [SQL구문] 을 실행하면 된다. 기본적인 SQL 구문의 실행계획은 3가지가 존재한다.
- 테이블 풀 스캔(full scan)의 실행계획
- 인덱스 스캔(index scan)의 실행계획
- 간단한 테이블 join의 실행 계획
아래 코드에서 sequential scan이 테이블 풀 스캔을 의미한다.
EXPLAIN select * from users_user;
-- Query Plan 결과
-- Seq Scan on users_user (cost=0.00..4989.31 rows=117831 width=219)
아래는 인덱스 스캔의 예시이다.
EXPLAIN select * from users_user where id = 3000;
-- Query Plan 결과
-- Index Scan using users_user_pkey on users_user (cost=0.42..8.44 rows=1 width=219)
-- Index Cond: (id = 3000)
아래의 join 실행계획은 일반적으로 트리구조이다. 중첩 단계가 깊을수록 먼저 실행되며, 같은 중첩 단계일 경우 위에서 부터 실행된다. users_user를 풀 스캔하고, users_userreview를 풀스캔하고, 해시 알고리즘을 사용하는 순서로 실행되었다.
EXPLAIN select *
from users_userreview t1
join users_user t2 on t2.id = t1.user_id
-- Query Plan 결과
-- Hash Join (cost=10030.20..196060.81 rows=3654042 width=290)
-- Hash Cond: (t1.user_id = t2.id)
-- -> Seq Scan on users_userreview t1 (cost=0.00..87228.42 rows=3654042 width=71)
-- -> Hash (cost=4989.31..4989.31 rows=117831 width=219)
-- -> Seq Scan on users_user t2 (cost=0.00..4989.31 rows=117831 width=219)
참고로 위에서 얻은 레코드 수(rows)는 카탈로그 매니저로부터 얻은 값이라 실제 테이블 레코드 수와는 차이가 있을 수 있다. 실제로 테이블의 모든 레코드를 삭제하고 실행 계획의 레코드 수를 봐도 삭제하기 전의 레코드 수가 출력될 수 있다.
View
select 구문 중에서도 자주 사용하는 구문은 텍스트 파일에 따로 저장해놓아도 좋을 것이다. select 구문을 DB 안에 저장할 수 있는 기능을 제공하는데 이 기능을 View 라고 한다. 테이블을 쿼리할 때와 똑같이 사용하면 되는데 테이블을 가지고 있지 않고 내부적으로 select 구문을 nested 하게 실행하는 구조가 된다.
CREATE VIEW CountAddress (v_address, cnt) AS
SELECT address, COUNT(*) FROM Address GROUP BY address;
SELECT v_address, cnt FROM CountAddress;
조건 분기, 집합 연산, 윈도우 함수
조건분기 구분 중 대표적으로 CASE 식은 SQL 성능과도 깊은 연관이 있어서 자주 사용된다.
select id,
login_type,
case
when login_type = 'kakao' then '카카오'
when login_type = 'naver' then '네이버'
else '없음'
end as login_type_korean
from users_user
limit 10
집합 연산은 대표적으로 UNION으로 합집합을 구하거나(양쪽 테이블에서 중복을 제거하여 보여줌) INTERSECT로 교집합을 구하거나(양쪽 테이블에서 공통으로 존재하는 레코드만 보여줌) EXCEPT로 차집합을 구할 수 있다.
윈도우 함수는 aggregation이 없는 GROUP BY 구라고 생각하면 된다. GROUP BY 구절은 특정 컬럼으로 grouping 하여 각 그룹에 속한 데이터의 값을 하나로 aggregation 하는데, 대표적으로 COUNT, SUM, AVG, MIN, MAX 등의 함수가 있다. 윈도우 함수는 이를 PARTITION BY 라는 구로 수행하는데 GROUP BY와 차이점이 있다면 자른 후에 집약하지 않으므로 출력 결과의 레코드 수가 입력되는 테이블의 레코드 수와 같다는 것이다. 윈도우 함수의 기본적인 구문은 집약 함수 뒤에 OVER 구를 작성하고 내부에 자를 키를 지정하는 PARTITION BY 또는 ORDER BY 를 입력하는 것이다.
select id, login_type, count(*) over(partition by login_type) cnt
from users_user
윈도우 함수로 사용할 수 있는 함수로는 COUNT 또는 SUM 과 같은 일반 함수 이외에도 윈도우 함수 전용 함수로 제공되는 RANK 또는 ROW_NUMBER 등의 순서 함수가 있다.
select id, login_type, point, rank() over(order by point) as rnk
from users_user
RANK 는 순서를 건너뛰는 경우가 있는데 건너뛰는 작업 없이 구하고 싶을 때 DENSE_RANK 를 사용하면된다.
select id, login_type, point, dense_rank() over(order by point) as rnk
from users_user
예시로 문제를 푼 유저 중에서 날짜 별로 푼 문제 수의 비율을 구하는 SQL문은 다음과 같다.
select date(created), count(*), count(*) / sum((count(*))) over ()
from problems_solvedproblem
group by date(created);